
There’s no Consent in AI
How unchecked AI development exploits creators and compromises data integrity.


There is no doubt that we are living in an era of the AI boom. A quick look at Hugging Face, the most popular website for AI models and training datasets, shows the attention dedicated to this area is vital.
In September 2022, it hosted “only” 68,000 models, by the beginning of 2024, that number shot to well over 350,000. It currently sits at almost 800,000 models and over 180,000 datasets available. That’s a staggering growth rate in less than two years.
However, while the AI industry celebrates innovation, the conversation around ethics and consent remains largely ignored. With new models and datasets constantly emerging, little oversight exists regarding the origins of this data and whether its inclusion is ethical.
But what’s even more concerning is the secrecy. Since they treat the model weights and training data as a trade secret, it’s all a black box to the outside world. Today’s blog is about a different aspect of data provenance — consent and why it matters when training AI.
AI’s Data Problem: Take, Sell, Profit!
A consent layer for AI just doesn’t exist, said Mat Dryhurst, who co-founded Spawning, an organization developing the opt-out feature, for the Algorithm.
Not long ago, this became once again painfully obvious. Proof News published an article about how a dataset called “Pile”, compiled by the organisation EleutherAI, found its way into training AI heavyweights such as Nvidia, Salesforce, and Anthropic.
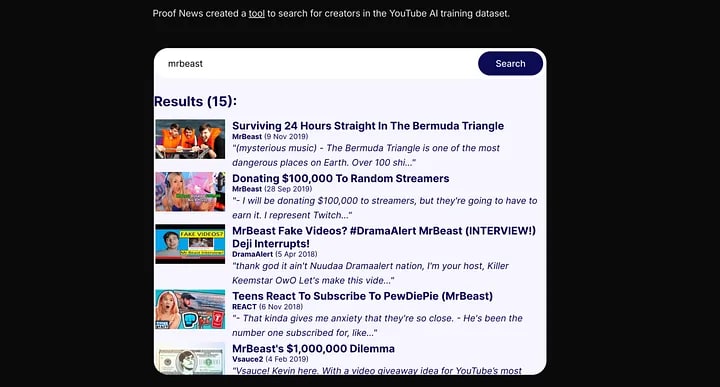
Their investigation found that 173,536 YouTube videos from over 48,000 channels were scraped for subtitles and used as training data for various models.
What is troubling is that none of the 48,000+ channel owners were informed in any way that their content was being used for AI training. None of them were given a choice or any form of compensation. The story is almost identical to another infamous dataset used in Pile: “Books3”.
Artists and content creators, whose creations end up in the maws of giant data centres without their approval, are already acutely aware of the implications generative AI could have on their work.
“Studios may use generative AI to replace as many of the artists along the way as they can. This will be used to exploit and harm artists.” — Dave Wiskus commented for Proof News
His statement shows exactly what the problem is with the current modus operandi: appropriation without consent and/or compensation and repackaging and reselling of the stolen content with far less costs for the end consumer, which puts a stranglehold on the already strained livelihoods of artists and creators.
Of course, there are cases where copyrighted material can be used in AI model trainings. Henderson et al. note in their Foundation Models and Fair Use (2023) that “in the United States and several other countries, copyrighted content may be used to build foundation models without incurring liability due to the fair use doctrine”.
If the content is used to create something unique and transformative, it falls under fair use.
Generative AI, on the other hand, produces results that are very similar to the input data, and things enter into a grey area. It will largely be up to the courts to decide what fair use and copyright infringement is in the plethora of AI cases brought against their owners.
Until then, individuals will have to deal with a powerful industry with its sights set on further developments.
The Role of Platforms: The Middleman Problem
The good thing is that due to the many legal disputes brought against them, AI companies realise that the internet is not an all-you-can-eat buffet to help yourself to.
OpenAI’s recent agreements with Reddit and Stack Overflow grant them access to vast user-generated content. However, this (still) raises ethical concerns: Reddit and Stack Overflow users were not consulted about their data being sold.
This was evident from the strong community backlash on both platforms, since the users generate all the content sold. This puts the individual creator at a serious disadvantage and leaves them with only one real choice: use it, or leave it.
Platforms are responsible for protecting their users, yet many continue to allow AI companies to scrape data freely. For instance, YouTube still grants API access to subtitles despite ethical concerns.
Possible solutions include:
- Clear, concise terms of service that explicitly address AI training.
- Opt-in mechanisms that allow users to control how their data is used.
- Platform-driven efforts to negotiate fair compensation for content creators.
Of course, it’s complicated for AI companies to obtain training data on a large scale while obtaining consent from individuals. But in the digital age, finding a consent solution is neither the root cause nor an excuse for this unfair imbalance.
Meaningful Consent in The New Age
We have only focused on the creative industries in this blog, and a very narrow subset of problems that arise from ignoring consent. The scope of consent in AI is much broader.
It doesn’t take too much imagination to see how extremely problematic disregarding consent becomes when we shift our attention to bioethics, medicine or public services that deal with highly personal and sensitive data.
Another issue intertwined with consent is privacy. LLMs are extremely powerful in finding patterns. As Caitlin Chin-Rothmann from CSIS points out, algorithms can infer intimate details about a person even from large, anonymised datasets.
This carries increased risks for harm, such as scams, companies could choose to treat people differently (e.g., charge them higher insurance premiums, or they could be subject to wrongful state surveillance) if the algorithms produce a false flag.
The list goes on and it clearly shows that not including a clear consent option when collecting AI training data can have consequences that extend well beyond immediate monetary compensation.
So, what should a meaningful consent solution look like? Since the GDPR came into force, consent has been clearly defined: it must be a freely given, specific, informed and unambiguous indication of a person’s agreement to their data processing.
This means that the data subject must have a genuine, granular choice, an unambiguous decision and clear information that supports that decision. Renowned organisations such as MyData already have consent-gathering solutions which adhere to GDPR’s demands.
Some potential solutions include:
- Data unions: Groups of individuals collectively negotiating how their data is used.
- Blockchain-based consent tracking: Immutable records of data permissions.
- Opt-in AI training protocols: AI companies should default to exclusion unless explicit consent is given.
Another unexplored avenue is data unions, where data subjects could pool their data and enter into an agreement with AI companies as a collective. Blockchain and Web3 are natural candidates enabling such solutions — DAOs could act as a base layer infrastructure for data unions.
Datafund, as a Web3 company, has also developed a solution called the Datafund app, where individuals or organisations can privately upload their models or datasets and be instantly compensated for their use.
Datafund’s Consent Receipt Suite is another way for organisations to store consent for data usage in an immutable way.
A white paper from King and Meinhardt (2024) also proposes three distinct suggestions for how to mitigate the risks to data privacy posed by the development and adoption of AI:
- Opt-in data collection: Defaulting to privacy rather than automatic inclusion.
- Regulatory oversight: Transparent supply chains for AI training data.
- Governance mechanisms: New systems that automate user consent and rights management.
There is no lack of alternative paths forward, it’s the will to do it that’s lacking.
Opting-in to Fair Data
AI companies are still prioritising rapid product development over other, more serious issues that stem from AI deployment and impact society as a whole.
Consent remains one of the core ethical considerations. This in turn has some far-reaching implications that should be seriously considered by the industry and legislators:
- Devaluation of creative industries: AI-generated content threatens the livelihood of artists, authors, and creators.
- Declining AI quality: Reduced human participation in creative fields could ultimately degrade AI’s output.
- Erosion of originality: AI-generated content risks homogenizing creativity and stifling innovation.
- Social repercussions: Unregulated AI training could reinforce biases, contribute surveillance overreach, and deepen social inequality.
There is also a risk of creating a digital divide between those who can protect their data and those who cannot, potentially exacerbating existing social inequalities.
There are unforeseen consequences as well, like the unexpected rise of right-wing extremism flamed by unregulated use of social media.
Prioritizing Ethics
AI continues to evolve, the industry must confront hard ethical questions. Prioritising consent and ethical considerations in the development of AI will transition to a fair data society — where the benefits of current technology are more evenly distributed.
Ultimately, AI’s trajectory depends on the choices we make now. Do we accept a system prioritizing corporate gains over individual rights, or do we demand transparency, accountability, and ethical AI development?
The future of AI is not just a technological issue — it is a moral one. The question is: will we act before it’s too late?
About the Creator
Gading Widyatamaka
Jakarta-based graphic designer with over 5 years of freelance work on Upwork and Fiverr. Managing 100s logo design, branding, and web-dev projects.
Keep reading
More stories from Gading Widyatamaka and writers in Futurism and other communities.
Why TikTok Users Move to Xiaohongshu
My FYP is filled with frustrated rants tearful goodbyes to TikTok, and now guides to basic Chinese phrases. The latter comes from the apparent exodus of TikTok users, in preparation for the platform’s ban on January 19th, to the Chinese app Xiaohongshu or “Red Note.”
By Gading Widyatamakaabout a year ago in Futurism
Neuralink: The Dawn of the Connected Mind or the Death of Private Thought?
The Last Frontier of Privacy For centuries, the human mind has been the only truly private place left on Earth. You can hide your browser history, you can encrypt your messages, and you can wear a mask in public. But your thoughts? Those were yours alone. No algorithm could touch them, and no surveillance camera could see them.
By Priyantha Wijethungaa day ago in Futurism
Best Email Marketing Strategies for 2026: The Inbox Guide
In the digital landscape of 2026, we are living through the "Great Algorithm Fatigue." Social media platforms have become unpredictable, and AI-powered search engines often summarize website content so effectively that users never actually click through to the source.
By Digistir3603 days ago in Futurism



Comments
There are no comments for this story
Be the first to respond and start the conversation.