
How an Artificial Intelligence Learned to Play Games
The ultimate evolution in the field of Artificial Intelligence.


So back in 2013 a group of intelligent coders and programmers at google acquired company name "DeepMind" took a really difficult challenge to develop an artificial intelligence-based Robot/System
Their goal was to create some that can play not just one but every single attari game and they developed a system they call DQN or Deep Q Network.
And after two years of struggle, it became the best Artificial Intelligent "Gammer"
It was so well developed that DQN was playing 13 times better than a normal attari game player at "Breakout"
17 times better at boxing and 15 times better at "video Pinball"
But there was one notable, exception. When DQN played "Montezuma's Revenge" It couldn't score a single point, even after playing for weeks and months.

Why it was so difficult for DQN to play "Montezuma's Revenge".
So what was the reason that made this particular game so vexingly difficult for DQN? and what would it take to solve it?
Before getting into that we need to understand that how DQN was playing the other games
It was something they called reinforcement learning. The AI system was designed to maximize some kind of numerical rewards. In this case, those rewards were simply the game's points.
This underlying goal drives the system to learn which buttons to press and when to press them to get the most points.
previously designed some AI systems used model-based approaches, where they have a model of the environment that they can use to predict what will happen next once they take a certain action.

How novelty became the key to success for DQN?
But in DQN's case, special thing was that it was a model-free artificial intelligence system. Instead of explicitly modeling the game environment, DQN just learns to predict, based on the images on screen, how many future points it can expect to earn by pressing different buttons.
for instance, "If the ball is here and I move left, more points but if I move right to more points"
But learning their connections requires a lot of trial and error. The DQN system would start by mashing randomly and then slowly piece together which buttons to mash and when in order to maximize its score
But in playing Montezuma's revenge, this approach of random button-mashing fell flat on its face. A player would have to perform this entire sequence just to score their points at the very end.
Just a single mistake? game over

So how could DQN even know it was on the right track?
In order to understand that we need to understand the behavior of a human child
In studies, we have found that infant consistently look at a picture, person, or anything they haven't seen before than ones they have there just seemed to be something intrinsically rewarding about novelty
this behavior has been essential in understanding the infant mind it also turned out to be the secret to beating "Montezuma's revenge"
The deepened researchers worked out an ingenious way to plug this preference for novelty into learning.
They made it so that unusual or new images appearing on the screen were every bit as rewarding as real in-game points
But there's a turn in this story.
Suddenly DQN was behaving totally differently from before it wanted to explore the room it was in, to grab the key and escape through the locked door not because it was worth 100 points,
But for the same reason we would:
yes it was to see what was on the other side
with this new drive, DQN not only managed to grab that first key it explored all the way through 15 of the temple's 24 chambers. but emphasizing novelty-based rewards can sometimes create more problems than it solves
A novelty-seeking artificial intelligence system that's played a game too long will eventually lose motivation.
if it has seen all before why go anywhere alternatively,
Actually AI having an existential crisis, makes it more human, and a lot scarier.
But if it encounters, say a television, it will freeze the constant novel images that are essentially paralyzing. Probably the most human-like behavior of them all.
The idea and inspiration here go in both directions.
So basically it did what a gamer would do. First, run, you just goof around trying to see every piece of the world, try to do all side quests and whatnot and once you are comfortable enough to speedrun the game, you lose interest and throw it away.
AI researchers stuck on a practical problem, like how to get DQN to beat a difficult game, are turning increasingly to experts in human intelligence for ideas.
At the same time AI is giving us new insights into the way we get stuck and unstuck: into boredom, depression, and addiction, along with curiosity, creativity, and play.
Hope you Enjoyed and learned something new from this article. Do Share this with your friends and I will see you in next post.
~Auri
About the Creator
Auri
My passion of writing not just the words but the feelings, emotion and the courage to develope myself everyday better then ever before can land you to some of the best writings for your buisness.
About Binding Prometheus
I want to start actively advocating on behalf of my own work, and the most valuable part of my canon is, without a doubt, Binding Prometheus, the play I have been working on since 2019 and only finished in 2023 as part of my MA. The play itself is an amalgamation of a million different inspirations. On one end, it evokes the Ancient Greek myth-play, deriving its own title from the earliest extant work of Western drama we have, Aeschylus’s Prometheus Bound. On the other end, it borrows significantly from the sci-fi bulwarks from over the years, namely Mary Shelley’s Frankenstein and Karel Capek’s Rossum’s Universal Robots. The play could be an episode of Black Mirror, I fear. I don’t know. I’ve only ever seen one episode of Black Mirror.
By Steven Christopher McKnight17 days ago in Futurism
Health Insurance Market: Preventive Care Focus, Value-Based Models & Industry Trends
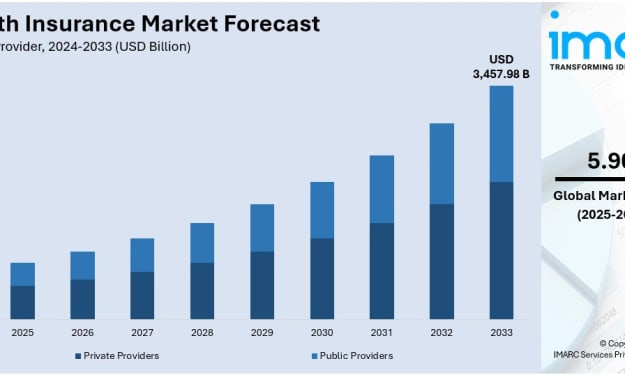
According to IMARC Group's latest research publication, global health insurance market size reached USD 1,949.84 Billion in 2024. Looking forward, IMARC Group expects the market to reach USD 3,457.98 Billion by 2033, exhibiting a growth rate (CAGR) of 5.90% during 2025-2033.
By Andrew Sullivan6 days ago in Futurism



Comments
There are no comments for this story
Be the first to respond and start the conversation.