
Understanding LLMs: Types, Versions, and Their Evolution
Large Language Model
Introduction:
Large Language Models (LLMs) have become a cornerstone of modern AI and natural language processing (NLP). These models are capable of understanding, generating, and manipulating human language in ways that were unimaginable a decade ago. From chatbots to content generation, LLMs are reshaping industries and revolutionizing how we interact with technology.
In this blog post, we’ll delve deep into the world of LLMs, exploring their different versions and types. We’ll also touch on their evolution, current applications, and what the future might hold for these powerful tools. By the end of this article, you should have a comprehensive understanding of LLMs and their significance in today’s technological landscape.
The Rise of Large Language Models
What Are LLMs?
A Brief History of LLMs
The journey of LLMs began with the development of simpler models like n-grams and Markov chains, which could generate text based on probabilities of word sequences. However, these early models were limited in their ability to understand context and long-term dependencies in language.
The real breakthrough came with the advent of deep learning and the introduction of models like the Recurrent Neural Network (RNN) and its variants, such as the Long Short-Term Memory (LSTM) and Gated Recurrent Unit (GRU). These models were capable of handling sequential data more effectively, paving the way for more sophisticated language models.
The true revolution, however, began with the introduction of the Transformer architecture by Vaswani et al. in 2017. This architecture, which forms the backbone of modern LLMs, enabled the creation of models like BERT (Bidirectional Encoder Representations from Transformers), GPT (Generative Pre-trained Transformer), and T5 (Text-To-Text Transfer Transformer). These models have set new benchmarks in NLP tasks, and their evolution continues to this day.
Types of Large Language Models
LLMs come in various forms, each with unique capabilities and use cases. Understanding the different types of LLMs is crucial for selecting the right model for your specific needs.
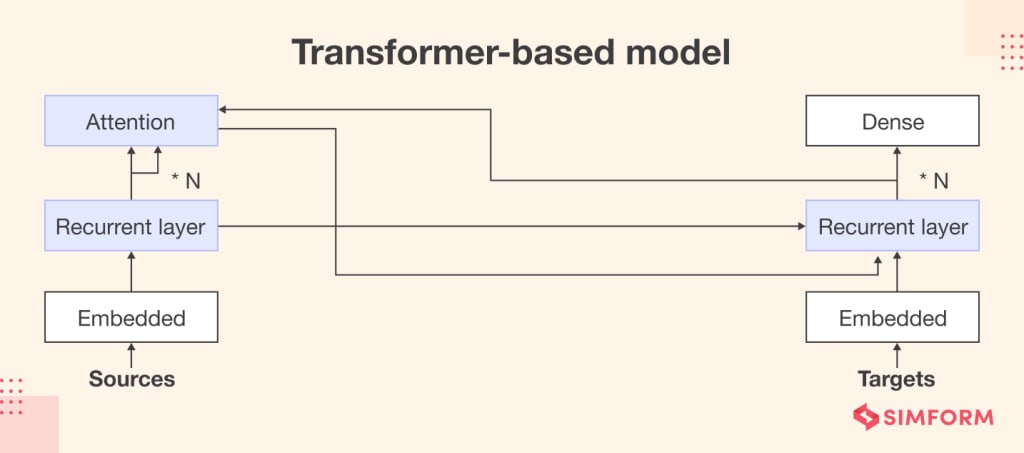
1. Transformer-Based Models

a. GPT (Generative Pre-trained Transformer):
GPT, developed by OpenAI, is one of the most well-known transformer-based models. It is an autoregressive model, meaning it generates text one word at a time, using the previous words as context. GPT models have evolved through several versions, with GPT-4 being the latest. These models are particularly useful for text generation, content creation, and conversation simulations.

b. BERT (Bidirectional Encoder Representations from Transformers):
BERT, developed by Google, is a bidirectional model, meaning it considers the entire context of a sentence when making predictions. Unlike GPT, which generates text in a left-to-right fashion, BERT analyzes text in both directions, making it highly effective for tasks like question answering, sentiment analysis, and language understanding.

c. T5 (Text-To-Text Transfer Transformer):
T5, also developed by Google, is a versatile model that frames all NLP tasks as a text-to-text problem. This means that tasks like translation, summarization, and classification are all treated as generating a piece of text. T5’s flexibility makes it a powerful tool for a wide range of applications.

2. Recurrent Neural Network (RNN)-Based Models
a. LSTM (Long Short-Term Memory):
LSTM is a type of RNN designed to overcome the limitations of traditional RNNs, particularly the vanishing gradient problem. LSTM models are capable of learning long-term dependencies in sequential data, making them useful for tasks like time-series prediction, speech recognition, and language modeling.
b. GRU (Gated Recurrent Unit):
GRU is a variant of LSTM that simplifies the architecture by combining the forget and input gates into a single update gate. GRUs are often faster to train than LSTMs and can achieve similar performance on many tasks, including language modeling and sequence prediction.
3. Convolutional Neural Network (CNN)-Based Models
a. TextCNN:
TextCNN is a model that applies convolutional neural networks to text data. While CNNs are typically associated with image processing, they can also be used for NLP tasks like text classification and sentiment analysis. TextCNN models capture local features of text, such as n-grams, making them effective for tasks where local context is important.
Evolution of LLMs: A Timeline
Early Beginnings: N-Grams and Markov Chains
Before the advent of neural networks, simpler statistical models like n-grams and Markov chains were used for language modelling. These models were limited by their inability to capture long-term dependencies in language, leading to often disjointed and nonsensical text generation.
The Emergence of Neural Networks: RNNs and LSTMs
The development of Recurrent Neural Networks (RNNs) marked a significant step forward in language modelling. RNNs introduced the concept of memory, allowing the model to retain information about previous words in a sequence. This made it possible to generate more coherent and contextually appropriate text.
However, RNNs struggled with long-term dependencies due to the vanishing gradient problem. This led to the development of Long Short-Term Memory (LSTM) networks, which introduced gating mechanisms to better manage the flow of information. LSTMs became the go-to model for sequence-related tasks, including language modelling and machine translation.
The Transformer Revolution
The introduction of the Transformer architecture in 2017 by Vaswani et al. revolutionized the field of NLP. Transformers replaced the sequential processing of RNNs with a parallel processing mechanism, enabling much larger and more powerful models to be trained.
BERT: The Rise of Bidirectional Models
In 2018, Google introduced BERT, a transformer-based model that significantly improved performance on a wide range of NLP tasks. BERT’s bidirectional approach, which considers both the left and right context of a word, allowed it to achieve state-of-the-art results in tasks like question answering and sentiment analysis.
GPT and Autoregressive Models
Around the same time, OpenAI was developing its transformer-based model, GPT. Unlike BERT, GPT is an autoregressive model, meaning it generates text one word at a time. The release of GPT-2 in 2019 and GPT-3 in 2020 showcased the incredible potential of these models for text generation, content creation, and even basic reasoning.
The Present and Future of LLMs
As of 2024, LLMs have continued to evolve, with models like GPT-4, PaLM (Pathways Language Model), and others pushing the boundaries of what is possible. These models are being integrated into a wide range of applications, from virtual assistants to creative writing tools.
Applications of LLMs
LLMs have a broad range of applications, from everyday tools to cutting-edge research.
1. Content Creation and Copywriting
One of the most popular applications of LLMs is in content creation. Models like GPT-4 are used by writers, marketers, and businesses to generate high-quality content, including blog posts, social media updates, and product descriptions. The ability to quickly generate coherent and engaging text has made LLMs an invaluable tool for content creators.
2. Chatbots and Virtual Assistants

LLMs power many of the chatbots and virtual assistants we interact with daily. These models enable natural language understanding and generation, allowing users to have more meaningful and productive interactions with AI-powered systems. From customer support to personal assistants, LLMs are improving the user experience across various platforms.
3. Translation and Localization
LLMs are also used in translation and localization services. Models like Google’s T5 can translate text between multiple languages with high accuracy, making them essential for businesses operating in global markets. The ability to understand context and nuance in language also allows these models to provide more accurate and culturally appropriate translations.
4. Sentiment Analysis and Market Research
Businesses use LLMs for sentiment analysis to gauge public opinion and market trends. By analyzing social media posts, reviews, and other user-generated content, LLMs can identify patterns and sentiments, helping companies make data-driven decisions. This application is particularly useful in marketing, product development, and customer service.
5. Medical Research and Healthcare

In the healthcare sector, LLMs are used for tasks like analyzing medical records, generating clinical reports, and even assisting in diagnosis. The ability of LLMs to process and understand complex medical terminology makes them valuable tools for medical research and patient care.
6. Education and E-Learning
LLMs are also being used in education to create personalized learning experiences. These models can generate customized study materials, answer student queries, and even grade assignments. By understanding the unique needs of each student, LLMs can help create more effective and engaging educational experiences.
Challenges and Limitations of LLMs
Despite their impressive capabilities, LLMs are not without challenges and limitations.
1. Ethical Concerns
One of the biggest challenges facing LLMs is the ethical implications of their use. These models can generate harmful or biased content if not properly monitored. There is also the risk of LLMs being used for malicious purposes, such as generating fake news or deepfake content. Addressing these ethical concerns is crucial for the responsible development and deployment of LLMs.
2. Resource-Intensive Nature
Training and deploying LLMs require vast computational resources, including powerful GPUs and large amounts of energy. The environmental impact of running these models at scale is a growing concern. Additionally, the cost of training state-of-the-art models like GPT-4 can be prohibitive, limiting access to these technologies to well-funded organizations. This resource-intensive nature also makes it challenging to continuously update and improve LLMs, as each iteration requires even more data and processing power.
3. Lack of Interpretability
LLMs, like many deep learning models, often operate as black boxes. While they can produce remarkably accurate and human-like text, understanding how they arrive at specific outputs is difficult. This lack of interpretability can be problematic in scenarios where transparency and accountability are critical, such as in legal or medical applications. Researchers are actively working on methods to make these models more interpretable, but this remains an ongoing challenge.
4. Data Dependency and Bias
The performance of LLMs is heavily dependent on the quality and quantity of the data they are trained on. If the training data is biased or lacks diversity, the model will reflect those biases in its outputs. This can lead to unintended consequences, such as reinforcing stereotypes or making discriminatory decisions. Mitigating bias in LLMs requires careful data curation and the development of techniques to detect and correct biases during training and deployment.
5. Limited Understanding of Context
While LLMs are incredibly powerful, they still struggle with understanding nuanced context, especially when dealing with ambiguous or abstract concepts. These models rely heavily on patterns learned from training data, which means they can sometimes produce outputs that seem coherent but are contextually inappropriate or nonsensical. This limitation highlights the difference between genuine understanding and statistical prediction, a gap that current LLMs have yet to bridge fully.
6. Security Risks
LLMs can be vulnerable to various security risks, including adversarial attacks where malicious inputs are designed to trick the model into producing harmful or incorrect outputs. Additionally, the widespread use of LLMs in applications like chatbots and virtual assistants raises privacy concerns, as these models often process sensitive information. Ensuring the security and privacy of users while leveraging the capabilities of LLMs is a critical challenge for developers.
The Future of LLMs
Despite these challenges, the future of LLMs is promising, with ongoing research and development aimed at addressing current limitations and expanding the capabilities of these models.
1. More Efficient Training Methods
Researchers are exploring more efficient training methods that can reduce the computational resources required to develop LLMs. Techniques like model distillation, where a smaller model is trained to mimic the behavior of a larger one, are being used to create more resource-efficient models without sacrificing performance. Additionally, advances in hardware, such as specialized AI chips, are expected to further reduce the energy consumption and cost of training LLMs.
2. Improved Interpretability
Improving the interpretability of LLMs is a major focus for researchers. Techniques such as attention visualization, which highlights the parts of the input text that the model is focusing on, are helping to make these models more transparent. Another approach involves developing models that can explain their reasoning process in human-understandable terms, which could significantly enhance trust and usability in critical applications.
3. Addressing Bias and Ethical Concerns
As awareness of the ethical implications of LLMs grows, more efforts are being made to address bias and ensure fairer outcomes. This includes developing better data curation practices, implementing bias detection algorithms, and creating guidelines for the responsible use of LLMs. Organizations like OpenAI and Google are also working on policies and tools to prevent the misuse of their models.
4. Hybrid Models and Multimodal LLMs
The future of LLMs may involve hybrid models that combine different types of neural networks to leverage their respective strengths. For instance, integrating transformer-based models with convolutional or recurrent networks could lead to more powerful and versatile LLMs. Additionally, multimodal models that can process not just text but also images, audio, and other data types are gaining traction. These models could revolutionize fields like content creation, virtual reality, and human-computer interaction.
5. Real-Time Adaptation and Personalization
LLMs of the future could become more adaptive and personalized, learning and evolving in real-time based on user interactions. This could lead to highly customized virtual assistants that cater to individual preferences and needs, providing more relevant and contextually appropriate responses. Real-time adaptation could also improve the performance of LLMs in dynamic environments, such as customer service or emergency response scenarios.
6. Collaborative Intelligence
One exciting area of research is collaborative intelligence, where LLMs work alongside humans to solve complex problems. Instead of replacing human intelligence, these models could enhance it by providing insights, generating ideas, and automating routine tasks. This collaboration could lead to breakthroughs in fields like scientific research, creative arts, and engineering, where human intuition and creativity are complemented by the computational power of LLMs.
Conclusion: The Evolving Role of LLMs in Society
Large Language Models have come a long way from their early beginnings, evolving into sophisticated tools that are transforming various industries. From content creation and customer service to medical research and education, the applications of LLMs are vast and continue to grow. However, with great power comes great responsibility, and the challenges associated with LLMs — such as ethical concerns, resource demands, and security risks — must be carefully managed.
As we look to the future, the continued evolution of LLMs will likely bring about even more innovative applications and opportunities. By addressing current limitations and embracing new advancements, we can harness the full potential of LLMs while ensuring their responsible and ethical use. Whether in the hands of researchers, developers, or everyday users, LLMs will undoubtedly play a central role in shaping the future of technology and society.
About the Creator
Rabbi Shlomo Slatkin, M.S., LCPC on Imago Dialogue, Repair, and Relationship Safety
Rabbi Shlomo Slatkin, M.S., LCPC, is founder and therapist at The Marriage Restoration Project in the Baltimore area. An ordained rabbi and Certified Imago Relationship Therapist and workshop presenter, he guides couples through intensives, retreats, and counseling aimed at restoring safety, communication, and connection after conflict or crisis. He holds a master’s in Counseling Psychology from Loyola University Maryland and trained with the Imago Relationship Institute. Slatkin earned a B.A. in Middle Eastern Studies, with undergraduate study at George Washington University and Oxford, and authored The Five Step Action Plan to a Happy & Healthy Marriage. He also co-edited curricula.
By Scott Douglas Jacobsen2 days ago in Education
Beyond the Resume: How to Assess Startup Teams When Backgrounds Fall Short
Investors and partners often begin evaluating startup teams by scanning resumes, titles, and past employers. While experience offers helpful signals, it rarely tells the full story in early-stage ventures. Startups operate in uncertain environments where adaptability and judgment matter as much as credentials. Therefore, relying solely on experience can lead to missed opportunities or misplaced confidence.
By Rushi Manche2 days ago in Education




Comments (2)
Nice analysis
Interesting piece