
Roadmap to Becoming a Data Engineer
A Step-by-Step Guide to Mastering the Skills and Tools Required for a Career in Data Engineering

Becoming a data engineer requires technical expertise, a deep understanding of data, and the ability to build and optimize complex systems. Here’s a detailed roadmap to help you achieve this goal:
1. Understand the Role of a Data Engineer
Before starting, understand what a data engineer does. These professionals design, build, and maintain data infrastructure systems that allow for the analysis of large datasets. Their work involves integrating data from multiple sources, creating efficient pipelines, and optimizing databases. Understanding the responsibilities of this role helps you set clear goals and focus your learning on the right areas.
2. Study Programming Fundamentals
Programming is essential for data engineers. Key technologies include:
- Python: A versatile language for data manipulation, scripting, and integration. Libraries like Pandas and NumPy make it ideal for small-scale data processing.
- Java/Scala: These languages are essential for working with big data frameworks like Apache Spark, where performance and scalability are crucial.
- SQL: The foundation of querying and managing relational databases. Learn how to write complex queries, joins, and subqueries for efficient data extraction.
Start with basic courses and progress to solving real-world problems on platforms like LeetCode or HackerRank.
3. Familiarize Yourself with Databases
Databases are at the heart of data engineering. Essential tools include:
- MySQL and PostgreSQL: Relational databases that are widely used for structured data storage. Learn to design schemas, write efficient queries, and optimize indexes.
- MongoDB: A NoSQL database suited for unstructured or semi-structured data, like JSON documents. It's scalable and flexible for various use cases.
- Snowflake and BigQuery: Modern cloud-based data warehouses optimized for analytics and querying massive datasets.
Practice setting up and querying these databases to understand their strengths and trade-offs.
4. Learn Cloud Infrastructure
Modern data engineering heavily relies on cloud platforms. Focus on:
- AWS: Learn services like S3 (object storage), Redshift (data warehouse), and Glue (ETL tool). These are commonly used for scalable, cloud-based solutions.
- Google Cloud Platform (GCP): Explore BigQuery (data warehouse), Dataflow (streaming and batch processing), and Dataproc (managing big data clusters).
- Microsoft Azure: Study Data Lake (large-scale storage) and Synapse Analytics (data integration and analysis platform).
Cloud platforms are integral for handling distributed systems and large-scale datasets efficiently.
5. Master Data Manipulation
Data engineers spend significant time processing and transforming data. Key tools include:
- Pandas: A Python library for small-scale data manipulation. It is excellent for cleaning and preparing data for analysis.
- Apache Spark: A distributed computing framework for processing massive datasets. Use PySpark (Python API) to write scalable data pipelines.
- ETL Tools: Tools like Apache Nifi, Talend, and dbt allow you to build Extract, Transform, and Load (ETL) pipelines that automate data workflows.
Practice transforming datasets from different formats (e.g., CSV to JSON) and optimizing pipelines.
6. Study Data Modeling and Storage
Efficient data storage and retrieval require careful design. Focus on:
- Schema Design: Learn techniques like the star schema and snowflake schema for designing analytical databases.
- Data Lakes: Platforms like AWS S3 and Azure Data Lake store vast amounts of unstructured data, making it accessible for big data processing.
- OLTP vs. OLAP: Understand the difference between transactional (OLTP) systems and analytical (OLAP) systems. This helps in designing databases for specific use cases.
Learn to balance performance, cost, and scalability while designing storage systems.
7. Learn Data Integration Tools
Integration tools automate and streamline data workflows. Explore:
- Apache Airflow: A workflow orchestration tool for scheduling and monitoring ETL jobs.
- Apache Kafka: A real-time data streaming platform. It is highly scalable and ensures low-latency processing of events.
- Talend: An intuitive ETL tool for integrating and transforming data from multiple sources.
Set up pipelines that move data between systems while ensuring data quality.
8. Understand Big Data Concepts
Big data tools are vital for handling large-scale datasets. Study:
- Apache Hadoop: A framework for distributed storage (HDFS) and processing of large datasets.
- Apache Spark: Offers faster data processing compared to Hadoop, with capabilities for both batch and real-time workloads.
- HDFS: The distributed file system used by Hadoop, designed to handle fault tolerance and large files.
Work on real-world datasets to learn how to distribute computation and manage resources.
9. Work on Real-World Projects
Applying your knowledge is key. Example projects:
- Building a pipeline that collects, cleans, and stores social media data for sentiment analysis.
- Designing a system that predicts stock prices based on historical and real-time data.
- Document your process to showcase your technical and problem-solving skills.
10. Earn Certifications
Certifications validate your expertise and boost your credibility. Popular certifications include:
- AWS Certified Data Analytics
- Google Professional Data Engineer
- Databricks Certified Associate Developer for Apache Spark
These certifications demonstrate your skills to potential employers.
11. Learn Data Security Practices
Secure data management is critical. Focus on:
- Encryption: Protect sensitive data during storage and transmission.
- Access Control: Implement role-based access to restrict data visibility.
- Compliance: Understand regulations like GDPR (EU) and CCPA (California) to handle data responsibly.
Mastering these practices ensures your solutions are robust and trustworthy.
12. Develop Soft Skills
Soft skills are as important as technical expertise. Work on:
- Communication: Clearly explain complex systems to non-technical stakeholders.
- Collaboration: Work effectively in cross-functional teams with data scientists, analysts, and business managers.
- These skills will make you a well-rounded professional.
13. Stay Updated
Data engineering evolves rapidly. Stay current by:
- Following blogs like Towards Data Science and DZone.
- Participating in forums like Reddit’s r/dataengineering and Stack Overflow.
- Attending events like Big Data Summit and DataEngConf.
Continuous learning is essential to staying relevant in this dynamic field.
By following this roadmap and deepening your understanding of each technology, you’ll be well-prepared for a successful career as a data engineer.
Learn About Operating Systems
A solid understanding of operating systems, particularly Linux, is crucial for data engineers. Linux is widely used in servers, cloud platforms, and big data environments due to its performance, reliability, and open-source nature. Learn how to use the command line for tasks like file management, process control, and system monitoring. Additionally, familiarize yourself with system administration, including user management, permissions, network configuration, and installing software packages. Tools like Bash scripting can further enhance your efficiency in automating repetitive tasks. Mastering these skills ensures that you can effectively manage and troubleshoot the systems hosting your data pipelines and applications.
About the Creator
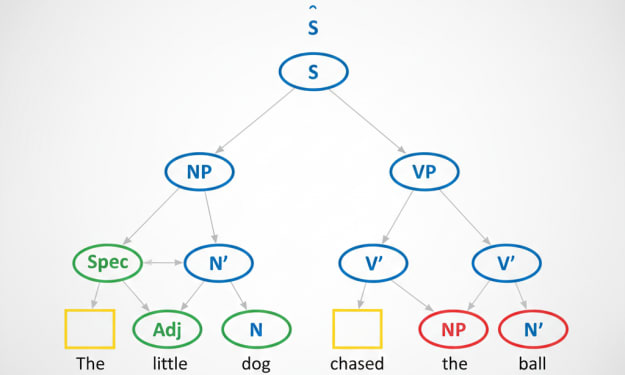
Mastering X-Bar Theory in Grammar in 10 Minutes
Grammar can often feel like a maze of confusing rules, especially when we dive into syntax — the study of sentence structure. One of the foundational tools in modern linguistics is X-Bar Theory, a framework that helps explain how words and phrases combine to form sentences. While it might sound intimidating, understanding X-Bar Theory can become straightforward if approached step by step.
By Games Mode Onabout 17 hours ago in Education


Comments
There are no comments for this story
Be the first to respond and start the conversation.