
Classification using XGBoost
Learn how to use XGBoost for classification and what makes it amazing

XGBoost is an optimized distributed gradient boosting library designed to be highly efficient, flexible and portable. Originally written in C++, the package started being used by the ML community after they won a machine learning competition.
XGBoost dominates structured or tabular datasets on classification and regression predictive modelling problems.
What makes XGBoost amazing?
- The Speed and the performance
- It outperforms all the single-algorithm methods in ML competitions
- The algorithm is parallelizable which makes it to harness all the processing power of modern multi-core computers.
- Has achieved state of the art performance on variety of benchmark datasets
- It has a variety of regularizations which helps in reducing overfitting
- Auto tree pruning – Decision tree will not grow further after certain limits internally
Before you begin classification with XGBoost, get yourself familiar with: Supervised learning, Decision Trees and Boosting.
Supervised learning:
- It is a subcategory of machine learning and artificial intelligence.
- It relies on labelled data.
- It uses some understanding of past behavior.
- The algorithm measures its accuracy through the loss function, adjusting until the error has been sufficiently minimized.
Decision Trees:
- It is a supervised algorithm used in machine learning composed of series of binary questions.
- It uses a binary tree graph where each node has two children and each data sample is assigned a target value. These target values are presented at the tree leaves.(where predictions happen)
- In each node a decision is made iteratively(one decision at a time) based on the selected sample's feature, to which descendant node it should go.
The following is an example of a Classification and Regression Tress(CART) used by XGBoost that classifies whether someone will like a hypothetical computer game X.
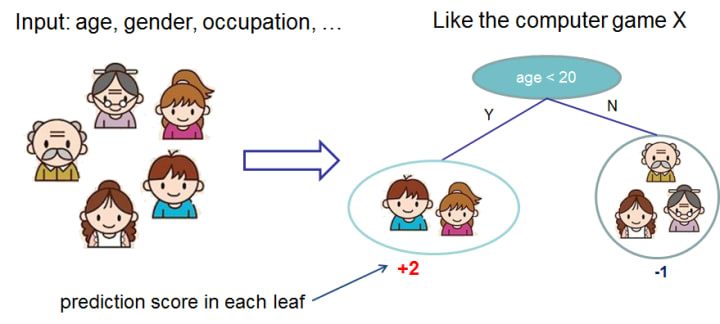
Usually, a single tree is not strong enough to be used in practice. Hence, XGBoost actually uses a ensemble model, which sums the prediction of multiple trees together.
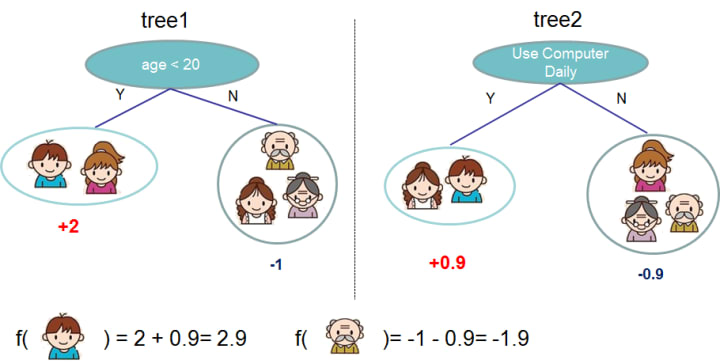
Boosting:
- It is not a specific machine learning algorithm
- XGBoost uses an ensemble boosting algorithm to convert many weak learners into an arbitrarily strong learner.
- It is accomplished by iteratively using a set of weak models on a subsets of the data and then each weak prediction is weighted according to each weak learner's performance. After that, the combined weighted predictions is used to obtained a single weighted predictions.
Fig2. is also a very basic example of boosting using two decision trees. Each tree in the figure is giving a different prediction score depending on the data it sees. After that, the prediction score for each possibility are summed across trees and the final prediction is simply the sum of the score from both the trees.
When to use XGBoost?
When not to use XGBoost?
Develop XGBoost Model in Python
The following is an example snippet on how to fit and predict a model using XGBoost on a choice of your dataframe (df):
Summary
In this post you discovered Supervised learning, Decision Trees, Boosting and how to develop your first XGBoost model in Python. XGboost has proven to be the most efficient Scalable Tree Boosting Method. It is a faster algorithm when compared to other algorithms because of its parallel and distributed computing. The objective of this library is to push computers to their boundaries in terms of computing in order to create a scalable, portable, and accurate library.
You also learned:
- What makes XGBoost amazing
- When to use XGBoost
- How to install XGBoost on your system ready for use with Python.
- How to prepare data and train your first XGBoost model on a standard machine learning dataset.
- How to make predictions and evaluate the performance of a trained XGBoost model
About the Creator
Keep reading
More stories from writers in Education and other communities.
Image-to-text technology, also known as Optical Character
Image-to-text technology, also known as Optical Character Recognition (OCR), has transformed the way we interact with visual information. It allows machines to extract text from images, enabling various applications across multiple industries. From digitizing printed documents to reading text from scanned images, OCR plays a vital role in making printed content accessible, editable, and searchable. The need for such technology has grown exponentially with the increasing reliance on digital data and the rapid shift from physical to digital content in nearly all sectors of life. As the digital world continues to expand, image-to-text technology has paved the way for more seamless workflows, enabling businesses and individuals alike to save time, effort, and resources.
By Alexander Jackson6 days ago in Education
A Dart at Dusk
Seconds ago, the sullen sun set on the two of us… my exuberant furry companion and me. A fresh breeze embraces us, delivering welcome relief from the day’s oppressive heat. His typical stumbling and staggering along — apace with a sloth — has turned into trip-trapping, high-stepping, almost skipping along.
By Angie the Archivist 📚🪶4 days ago in Petlife




Comments
There are no comments for this story
Be the first to respond and start the conversation.