
Cerebras Continues the Long March of Moores Law
Just when we thought that the era of doubling compute power every 18 months was at an end, Cerebras births a massive wafer - and China watches

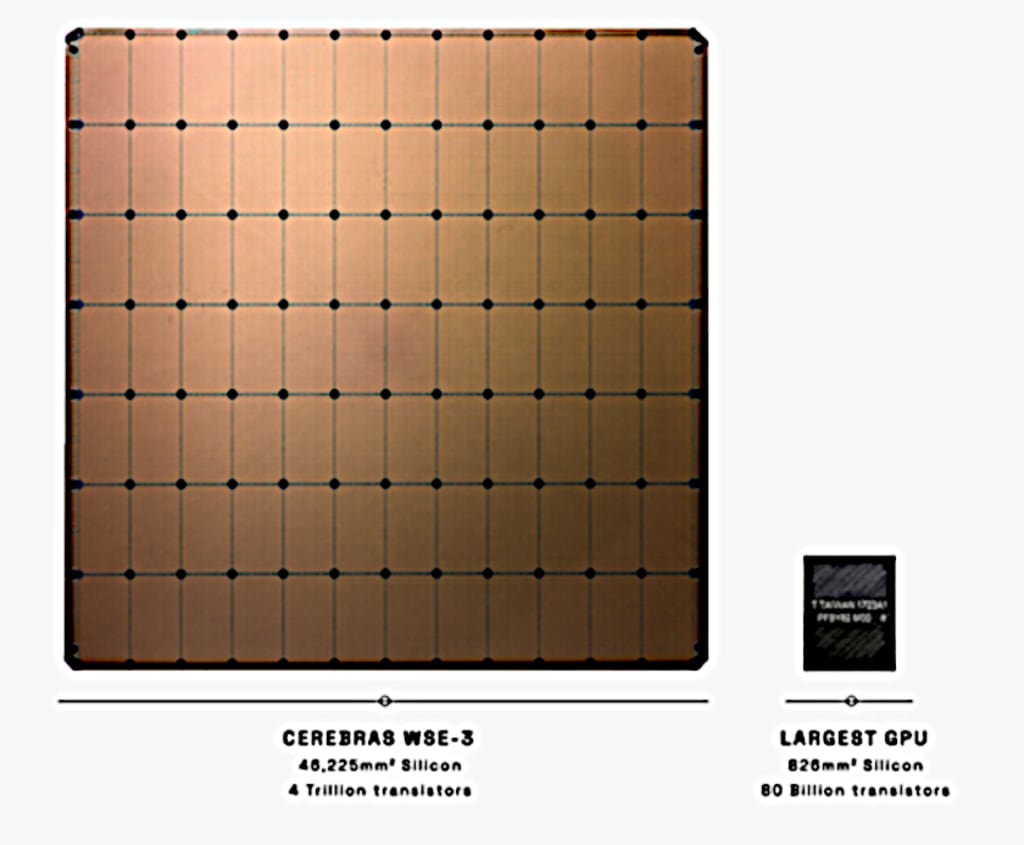
Historically, computer performance progress has been made by packing more and more devices — transistors — on to a chip. Wafer integration is reaching the physical limits of what can be fabricated, with just 2 nanometre (nm) between devices now being achieved. To do this fabricators use export-restricted extreme ultra-violet lithography machines from Dutch company ASML. China would love to have them.
These latest 2nm chips are underpinning the exponential growth of power-hungry AI systems.
But what do you do when you reach the physical limit?
Well, quantum computers can theoretically outperform those wafer-based systems. But they are highly sensitive and not likely to appear in the boxes that we use at home at any time in the foreseeable future.
There is another approach, which Cerebras has taken. Build outwards.
CPU and GPU chips have been getting bigger generation by generation. Cerebras has fabricated a 4 trillion transistor wafer using a 5nm TSMC process. What they call their third generation wafer-scale device, WSE-3, is imprinted with 900,000 cores and 44GB of SRAM.
TSMC is the world-leading semiconductor fabricator — ‘foundry’ — based in Taiwan, with a plant coming soon to the USA. As of 2022, TSMC held 53% of the world’s semiconductor market — Statista.

The size of a notepad computer, the installed WSE-3 wafer consumes a massive 27 kW (10 electric kettles) of power. So no, you will not be seeing this beast on your desktop. It will be used to power super computers and AI systems.
Cerebras WSE-3 specifications
Key Specs:
- 4 trillion transistors
- 900,000 AI cores
- 125 petaflops of peak AI performance
- 44GB on-chip SRAM
- 5nm TSMC process
- External memory: 1.5TB, 12TB, or 1.2PB
- Trains AI models up to 24 trillion parameters
- Cluster size of up to 2048 CS-3 systems
With a huge memory system of up to 1.2 petabytes, the CS-3 is designed to train next generation frontier models 10x larger than GPT-4 and Gemini. 24 trillion parameter models can be stored in a single logical memory space without partitioning or refactoring… — Cerebras
WSE-3 Capabilities
This is what Cerebras says about their new CS-3 compute unit which incorporates a single WSE-3 wafer:
The CS-3 compute unit is easily installed into a standard datacenter infrastructure — from loading dock to users’ hands in a few days rather than weeks or months.
The CS-3 connects to surrounding infrastructure over 12x standard 100 Gigabit Ethernet links and converts standard TCP-IP traffic into Cerebras protocol at full line rate to feed the WSE-3’s 900,000 cores.

They claim that a single CS-3 [1 wafer] typically delivers the wall-clock compute performance of many tens to hundreds of graphics processing units (GPU), or more. In one system less than one rack in size, the CS-3 delivers answers in minutes or hours that would take days, weeks, or longer on large multi-rack clusters of legacy, general purpose processors. It is said to pack the performance of a room full of servers into a single unit the size of a dorm room mini-fridge.
At the heart of the CS-3 system is an innovative wafer packaging solution we refer to as the engine block. The engine block delivers power straight into the face of the wafer to achieve the required power density that could not be achieved with traditional packaging. It provides uniform cooling for the wafer via a closed internal water loop. All cooling and power supplies are redundant and hot-swappable so you stay up-and-running at full performance. — Cerebras (ibid.)
But Cerebras’ systems are not necessarily faster than others in every scenario. The company’s CS-3 performance claims rely heavily on sparsity.
While Nvidia [HS-100] is able to achieve a doubling in floating point operations using sparsity, Cerebras claims to have achieved a roughly 8x improvement. — TheRegister
Sparsity?
In the context of GPU performance, sparsity refers to the proportion of zeros within a dataset or matrix used in computations. A sparse matrix has a high percentage of zeros compared to non-zero values.
Sparsity can impact GPU performance by reducing memory bandwidth usage. When dealing with sparse data, GPUs don’t need to access and process as many values, which can lead to significant savings in memory bandwidth usage. This is because GPUs have limited memory bandwidth compared to their computational power.
The WSE-3 has 44GB of super-fast on-chip SRAM deployed evenly across the entire surface of the chip. This gives every core single-clock-cycle access to fast memory at extremely high bandwidth — 21 PB/s (petabytes/second). This is 880x more capacity and 7,000x greater bandwidth than the leading GPU. (Cerebras, edited)
However, it’s worth noting that Cerebras’ CS-3 isn’t limited to clusters of 64. The company claims that it can now scale to up to 2,048 systems capable of pushing 256 AI exaFLOPS.
According to Feldman, such a system would be capable of training Meta’s Llama 70B parameter model in about a day. (TheRegister, ibid.)
Wafer-scale fabrication
Note that they use a 5 nm fabrication process. China is already using the 7 nm process and is trialling 5nm processes using available lithography technology that they have acquired (and are building).
China cannot buy the Dutch ASML 2nm extreme ultra violet (EUV) technology — it is subject to very strict export controls which the US Government has impressed on ASML via the Dutch government.
But now China will have a way to build superchips without the 2nm technology, and the US’s desperate efforts to stop China’s AI developments will be foiled.
China’s leading foundry, SMIC, recently announced achieving 5nm production for Huawei chips. However, there are caveats.
DUV lithography: Unlike leading non-China manufacturers who use EUV lithography for true 5nm processes, SMIC reportedly relies on DUV (deep ultraviolet) due to the US/Dutch export restrictions on acquiring EUV equipment.
Yield and performance: DUV lithography is less precise, potentially resulting in lower yields (usable chips per wafer) and reduced performance compared to EUV.
How important is the Cerebras development?
Well, for those companies (and countries) that believe AI is the future, then it is significant. But a technology leap? I’m not so sure. By focusing on 5 nm tech, Cerebras opens the doors for easier Chinese emulation of the integration technology. China will still want 2nm fabrication process capability, but probably just as quickly they can develop wafers akin to the WSE-3 using improved 5nm tech. That’s speculation on my part, of course.
The other side of the wafer is that we are starting to see cracks in the AI marketing blitz. There are signs that all will not be as forecast, and probably just as well. Very real problems are becoming apparent.
Apart from a deluge of lawsuits for plagiarism, there are very real concerns about hallucinations and other ‘data issues’.
Here's the well-known 'clock test' for AI.

Time will tell.
This is an edited version of my story originally published on medium.com
(c) James Marinero 2026. All rights reserved.
About the Creator
James Marinero
I live on a boat and write as I sail slowly around the world. Follow me for a varied story diet: true stories, humor, tech, AI, travel, geopolitics and more. I also write techno thrillers, with six to my name. More of my stories on Medium
Keep reading
More stories from James Marinero and writers in Journal and other communities.
Salt Typhoon and the Widespread Hacking of Western Telecoms Networks
China's Salt Typhoon campaign represents a fundamental shift in state-sponsored cyber espionage, moving away from the opportunistic targeting of individuals towards the systematic subversion of national telecommunications infrastructure. Attributed to contractors working for the Chinese Ministry of State Security based in Chengdu, this operation has exposed a profound structural vulnerability at the heart of Western democratic governance.
By James Marineroa day ago in Journal
Global Books Market Size & Forecast 2025–2033: A Timeless Industry Reinventing Itself for the Digital Age
Introduction: The Enduring Power of Books in a Rapidly Changing World Books have shaped civilizations, preserved cultures, and passed knowledge from one generation to the next for centuries. Even in an age dominated by short-form videos, social media, and artificial intelligence, the written word continues to hold its ground. The global books market is no longer just about ink and paper—it is a diverse ecosystem that spans printed books, e-books, audiobooks, academic texts, and digital platforms, serving readers of every age and background.
By Sakshi Sharmaabout 12 hours ago in Journal




Comments
There are no comments for this story
Be the first to respond and start the conversation.