


95% of Machine Learning solutions in the real world are for tabular data.
Not LLMs, not transformers, not agents, not fancy stuff.
Learning to do feature engineering and build tree-based models will open a ton of opportunities.
Machine learning engineers shouldn't only grow through years of hard work.
Learning this way is too slow and complacent.
You can grow much faster by actively:
- Collaborating with talented professionals
- Finding a mentor who is 2-5 years ahead
- Taking on ambitious projects outside of your comfort zone
Hard work can only take you so far, meanwhile leveraging a network and daring to take on challenges will 10x your growth.
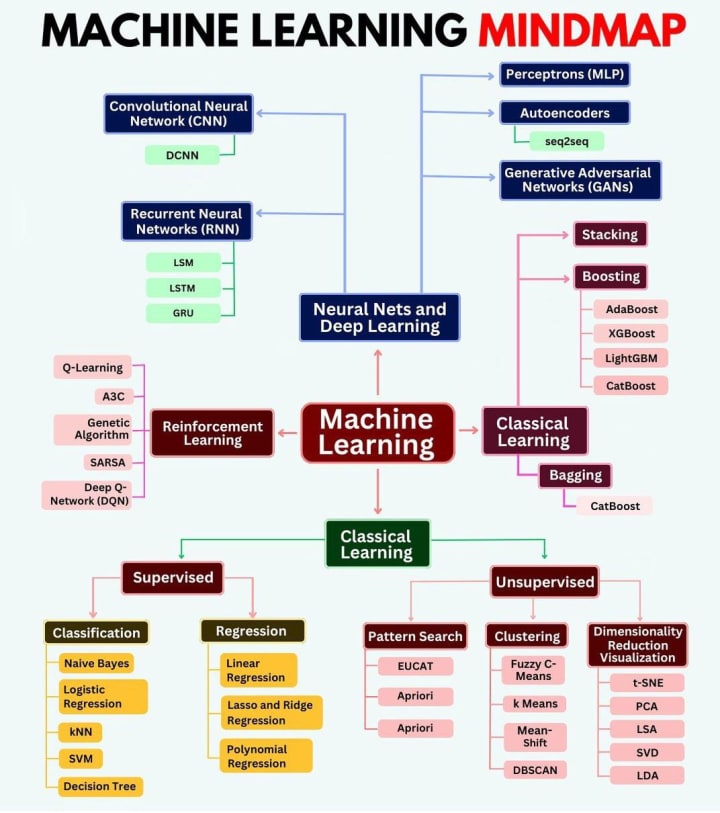
Here are 25 most common ML interview screening questions for each category:
1. Machine Learning fundamentals:
- Explain the difference between supervised, unsupervised, and reinforcement learning. Provide an example for each.
- What is the bias-variance tradeoff? How does it affect model performance?
- Describe the process of cross-validation. Why is it important in model evaluation?
- What is overfitting, and how can you prevent it in your models?
- Explain the concept of ensemble learning. What are bagging and boosting?
2. Statistics and Probability:
- Explain the difference between frequentist and Bayesian approaches in statistics.
- What is the Central Limit Theorem, and why is it important in machine learning?
- Describe the concept of hypothesis testing and its application in A/B testing.
- What is maximum likelihood estimation? Provide an example of its use in machine learning.
- Explain the difference between correlation and causation. How does this impact model interpretation?
3. Model Evaluation and Deployment:
- What metrics would you use to evaluate a classification model? How do they differ for balanced vs. imbalanced datasets?
- Describe the process of deploying a machine learning model in a production environment.
- What is A/B testing in the context of machine learning models? How would you design an A/B test?
- Explain the concept of model drift. How can it be detected and mitigated?
- What are the key considerations when scaling a machine learning system to handle large amounts of data or traffic?
4. Python for Machine Learning:
- How would you handle missing data in a pandas DataFrame?
- Explain the difference between a list and a numpy array in Python. When would you use one over the other?
- What are lambda functions in Python? Provide an example of how they can be used in data processing.
- Describe the purpose of the scikit-learn library. How would you use it to implement a simple classification model?
- What is the difference between *args and **kwargs in Python? How might they be useful in creating flexible ML functions?
5. Data Preprocessing:
- What is feature scaling, and why is it important? Describe different methods of feature scaling.
- How do you handle categorical variables in machine learning models? Explain one-hot encoding and label encoding.
- What is dimensionality reduction? Describe PCA (Principal Component Analysis) and its applications.
- How do you deal with imbalanced datasets? Discuss various techniques to address this issue.
- What is feature selection? Describe a few methods for selecting the most important features for a model.
Feature Scaling is one of the most useful and necessary transformations to perform on a training dataset, since with very few exceptions, ML algorithms do not fit well to datasets with attributes that have very different scales.
Let's talk about it 🧵
There are 2 very effective techniques to transform all the attributes of a dataset to the same scale, which are:
▪️ Normalization
▪️ Standardization
The 2 techniques perform the same task, but in different ways. Moreover, each one has its strengths and weaknesses.
Normalization (min-max scaling) is very simple: values are shifted and rescaled to be in the range of 0 and 1.
This is achieved by subtracting each value by the min value and dividing the result by the difference between the max and min value.
In contrast, Standardization first subtracts the mean value (so that the values always have zero mean) and then divides the result by the standard deviation (so that the resulting distribution has unit variance).
More about them:
▪️Standardization doesn't frame the data between the range 0-1, which is undesirable for some algorithms.
▪️Standardization is robust to outliers.
▪️Normalization is sensitive to outliers. A very large value may squash the other values in the range 0.0-0.2.
Both algorithms are implemented in the Scikit-learn Python library and are very easy to use.
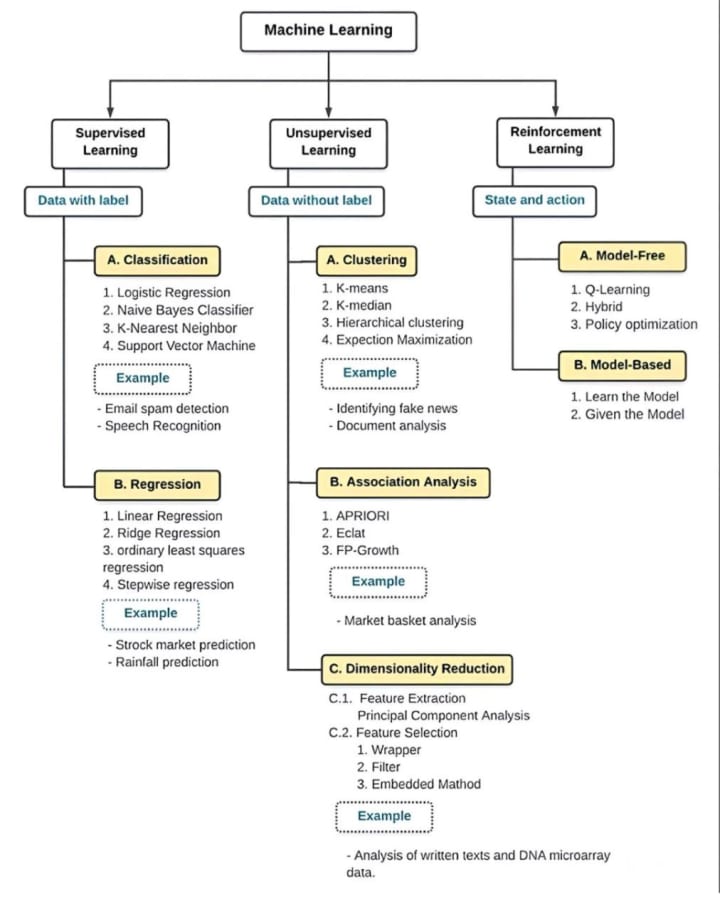
Types of Machine Learning Algorithms!
💡 Supervised Learning Algorithms:
1️⃣ Linear Regression: Ideal for predicting continuous values. Use it for predicting house prices based on features like square footage and number of bedrooms.
2️⃣ Logistic Regression: Perfect for binary classification problems. Employ it for predicting whether an email is spam or not.
3️⃣ Decision Trees: Great for both classification and regression tasks. Use it for customer segmentation based on demographic features.
4️⃣ Random Forest: A robust ensemble method suitable for classification and regression tasks. Apply it for predicting customer churn in a telecom company.
5️⃣ Support Vector Machines (SVM): Effective for both classification and regression tasks, particularly when dealing with complex datasets. Use it for classifying handwritten digits in image processing.
6️⃣ K-Nearest Neighbors (KNN): Suitable for classification and regression problems, especially when dealing with small datasets. Apply it for recommending movies based on user preferences.
7️⃣ Naive Bayes: Particularly useful for text classification tasks such as spam filtering or sentiment analysis.
💡 Unsupervised Learning Algorithms:
1️⃣ K-Means Clustering: Ideal for unsupervised clustering tasks. Utilize it for segmenting customers based on purchasing behavior.
2️⃣ Principal Component Analysis (PCA): A dimensionality reduction technique useful for simplifying high-dimensional data. Apply it for visualizing complex datasets or improving model performance.
3️⃣ Gaussian Mixture Models (GMMs): Suitable for modeling complex data distributions. Utilize it for clustering data with non-linear boundaries.
💡 Both Supervised and Unsupervised Learning:
1️⃣ Recurrent Neural Networks (RNNs): Perfect for sequential data like time series or natural language processing tasks. Use it for predicting stock prices or generating text.
2️⃣ Convolutional Neural Networks (CNNs): Tailored for image classification and object detection tasks. Apply it for identifying objects in images or analyzing medical images for diagnosis
About the Creator
Bahati Mulishi
Practical advice on remote work, IT careers, and professional skills to help you stay work-ready anywhere in the world.
Keep reading
More stories from Bahati Mulishi and writers in Geeks and other communities.
data science concepts
Data Cleaning: Data cleaning is the process of identifying and correcting or removing errors, inconsistencies, and inaccuracies in a dataset. It is a crucial step in the data science pipeline as it ensures the quality and reliability of the data.
By Bahati Mulishiabout a year ago in Geeks
A Knight of the Seven Kingdoms Series Review (Season 1)
As one of the biggest properties in fantasy, A Song of Ice and Fire remains immensely popular with audiences. After reaching far into the past with House of the Dragon, a second spin-off was on the cards. A Knight of the Seven Kingdoms serves up a bite-sized slice of action and drama, but it still claims a spot among the best small-screen titles.
By Robert Cain6 days ago in Geeks
Book Review: "The Complete Short Stories" by Robert Graves
Robert Graves has always been a divisive writer for me. I once found his book I, Claudius unreadable and yet, Goodbye to All That was fantastic. His historical novels seem to be the worst possible historical novels - no imagination has gone into them and they read more like a textbook of fictions rather than a historical fiction masterpiece. Whereas, when he wrote Goodbye to All That you can definitely feel that his writing style is one of brilliance and atmosphere. Oh, and I have not forgotten about the comments he made about a young Bob Dylan.
By Annie Kapur7 days ago in Geeks
A More Human Vocal
When we launched Vocal nearly a decade ago, the world was a very different place. LLMs did not exist, and stories were created one at a time by people sitting down to write, revise, and share something personal. Many of our assumptions about publishing, trust, and participation were built for a world where effort and output were inseparable.
By Justin @ Vocalabout 11 hours ago in Resources



Comments (1)
Thanks for sharing about machine learning. I liked it. If you wish you can subscribe me as well as I did to you 🥰