
Natural Language Processing (NLP)
Learn what's it about?

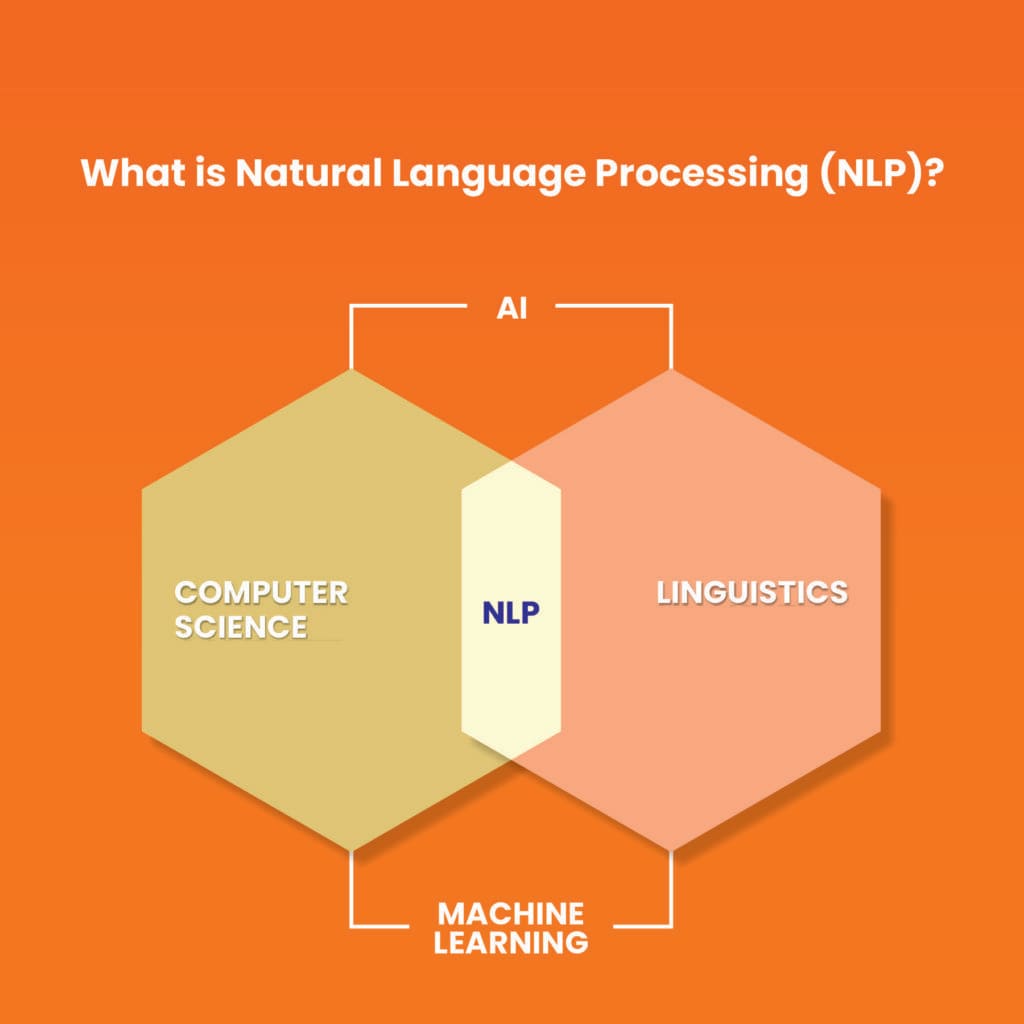
Natural Language Processing is a part of the curriculum of our Computer Science courses at Ambalika Institute of Management and Technology, one of the best engineering colleges in Lucknow.
Natural Language Processing (NLP) is an application of Artificial Intelligence (AI). Human language is complex and has many nuances, but we learn native languages instinctively and spontaneously through childhood and adolescence. How do we get computers to understand human language, without them having gone through this natural process, especially considering that there are many informal rules in human languages and computers do not innately have experience of intent or context? This is where NLP comes in. NLP is how a machine derives meaning from a language it does not natively understand, including interpreting context and intent through analysis.
NLP has reduced human dependency on computing systems to perform repetitive tasks. We can see examples of this in action in our everyday lives when we use email spam filters, autocorrect and predictive text, language translation software, Chatbots and smart assistants like Alexa, to name a few among hundreds of applications of NLP. Email spam filters were one of the first applications of Natural Language Processing. They employed the identification of certain words and phrases to indicate spam. Simple filters have now given way to automatic email classifications, such as that done by Gmail when it categorizes emails into Social, Promotions or Primary.
Applications of Natural Language Processing

The 4 stages in Natural Language Processing are:

Sentence Segmentation: Sentence segmentation is a foundational procedure in natural language processing (NLP) that involves dividing a given text into individual sentences. This process serves as the first step in many NLP tasks, as it provides the discrete units required for further analysis. Sentence segmentation is essential because the sentences identified during this stage are the fundamental building blocks transmitted to subsequent processing stages. These stages often include morphological analysis, part-of-speech tagging, syntactic parsing, and information retrieval. Despite its importance, sentence segmentation is sometimes overlooked in favor of more advanced NLP tasks. However, its accuracy directly impacts the overall performance of an NLP system, as errors in segmentation can propagate through the pipeline, affecting the quality of downstream tasks.
Word Tokenization: Word tokenization is the process of identifying word boundaries within a text, essentially determining where one word ends and the next begins. This step divides a text's continuous character sequence into smaller, meaningful units called tokens, which typically represent words. In computational linguistics, these tokens are the primary elements for processing text data. Word tokenization is a critical step in preparing data for analysis, enabling NLP models to understand and manipulate language effectively. Challenges in tokenization often arise in languages with complex or ambiguous boundary rules, such as those that do not use spaces to separate words. Advanced tokenization methods are required to handle such complexities, ensuring accurate representation of the text for further processing.
Parts of Speech: Parts of Speech (POS) tagging is the process of assigning a grammatical category—such as noun, verb, adjective, or adverb—to each word in a text. This task is fundamental to NLP as it provides insights into the syntactic and semantic structure of a sentence. By identifying the role of each word, POS tagging helps computers interpret human language with greater accuracy. This understanding is crucial for various NLP applications, including syntactic parsing, semantic analysis, and machine translation. For instance, knowing whether a word is a verb or a noun can guide the syntactic parsing of a sentence, aiding in the extraction of meaning. POS tagging often employs rule-based approaches, statistical models, or machine learning techniques to achieve high levels of accuracy, even in the presence of linguistic ambiguities.
Parsing: Parsing is a key process in natural language processing (NLP) that involves analyzing a sentence to understand its grammatical structure, meaning, and constituent elements. Essentially, parsing breaks down the input sentence into its fundamental components, such as nouns, verbs, phrases, and clauses, and determines how these elements are related to one another.
The primary objective of parsing is to uncover the syntactic structure of a sentence, which is typically represented in the form of a parse tree or dependency graph. These representations illustrate the hierarchical and relational organization of the sentence’s elements. For example, parsing identifies which words are subjects, objects, modifiers, or predicates and how they fit together to form a coherent structure.
Parsing plays a critical role in many NLP applications, including machine translation, question answering, sentiment analysis, and text summarization. By providing a detailed syntactic analysis, parsing enables systems to interpret the meaning of sentences more effectively. As a result, parsing serves as a crucial step in bridging the gap between human language and computational understanding.
So what is the future for NLP?
Natural Language Processing (NLP) is a rapidly developing field with wide-ranging applications in several industrial areas. The rapid rise in popularity of AI-driven technologies within certain areas can be ascribed to its exponential expansion.
Even while machine-generated solutions are advancing quickly, there are situations where producing uniquely workable answers requires thinking like a human. We enable smooth machine-to-machine communication by incorporating natural language processing (NLP) into AI frameworks. This allows for input provision and decision-making processes that are highly similar to human cognition.
Additionally, this encourages amicable machine-human contact, which facilitates cooperative problem-solving and the extraction of amazing results. Predictions indicate that NLP applications will play a significant role in important industries like healthcare in the near future.
About the Creator
Ambalika Institute
Ambalika Institute of Management and Technology (AIMT) was established in 2008 as a private engineering and management college in Mohanlalganj, Lucknow, Uttar Pradesh, India. It is affiliated with AKTU and BTE and is approved by AICTE.
Keep reading
More stories from Ambalika Institute and writers in Futurism and other communities.
Start Your Career in Science and Technology
In a world driven by rapid advancements in science and technology, embarking on a career in these fields can be a promising and rewarding journey. Whether you are a recent graduate contemplating your career path or someone seeking a fresh start, the opportunities in science and technology are boundless. Here are the steps to start your career in these exciting domains.
By Ambalika Instituteabout a year ago in Education
About Binding Prometheus
I want to start actively advocating on behalf of my own work, and the most valuable part of my canon is, without a doubt, Binding Prometheus, the play I have been working on since 2019 and only finished in 2023 as part of my MA. The play itself is an amalgamation of a million different inspirations. On one end, it evokes the Ancient Greek myth-play, deriving its own title from the earliest extant work of Western drama we have, Aeschylus’s Prometheus Bound. On the other end, it borrows significantly from the sci-fi bulwarks from over the years, namely Mary Shelley’s Frankenstein and Karel Capek’s Rossum’s Universal Robots. The play could be an episode of Black Mirror, I fear. I don’t know. I’ve only ever seen one episode of Black Mirror.
By Steven Christopher McKnight26 days ago in Futurism
3D Cell Culture Market: Tissue Engineering Demand, Cancer Research Focus & Market Forecast
Rising demand for physiologically relevant in-vitro models is accelerating adoption of 3D cell culture across drug discovery, toxicology, and regenerative medicine. According to IMARC Group's latest research publication, global 3D cell culture market size reached USD 2,643.1 Million in 2024. LAccording to IMARC Group's latest research publication, global 3D cell culture market size reached USD 2,643.1 Million in 2024. Looking forward, IMARC Group expects the market to reach USD 7,819.7 Million by 2033, exhibiting a growth rate (CAGR) of 12.69% during 2025-2033.
By sujeet. imarcgroup7 days ago in Futurism
Affection and Healing for Yourself
During the night of the last quarter moon, I gathered my ritual supplies. I carefully handled the chunk of black tourmaline that would protect me from your overall negative and narcissistic energy. I carefully walked the house with my stick of selenite in hand, asking the universe to cleanse our working space.
By Alisha Wilkins ✒️🦋🖋️8 days ago in Fiction




Comments
There are no comments for this story
Be the first to respond and start the conversation.