
Difference between K-Nearest Neighbor(K-NN) and K-Means Clustering
"Comparing K-NN and K-Means: Clustering vs. Classification"

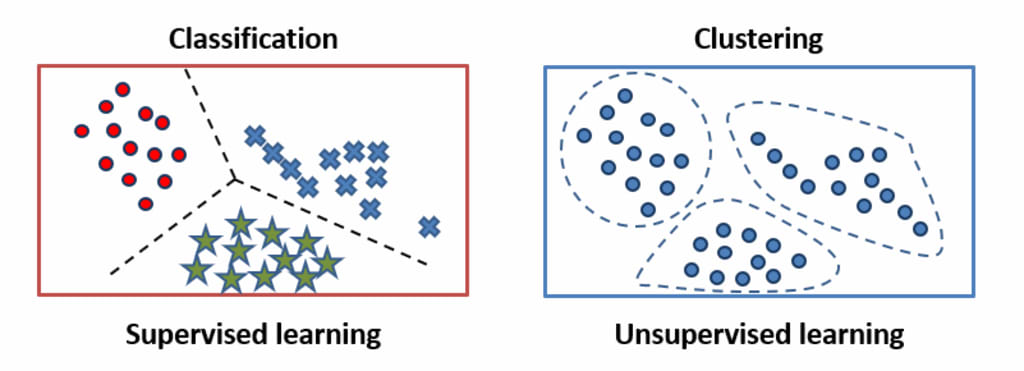
K-means and k-nearest neighbors are both popular machine learning algorithms, but they have different applications and operate in distinct ways.
K-means
K-means is an unsupervised clustering algorithm used for finding clusters in a set of data. The algorithm aims to partition a dataset into k distinct clusters where each observation belongs to the cluster with the nearest mean. The algorithm works by iteratively reassigning observations to the nearest centroid (mean) of their current cluster until the cluster assignments converge. The value of k is specified in advance, and the algorithm tries to find the k centroids that minimize the sum of the squared distances between each point and its assigned centroid.
K-nearest neighbors (k-NN)
K-nearest neighbors (k-NN), on the other hand, is a supervised algorithm used for classification or regression. Given a new data point, the algorithm finds the k nearest neighbors in the training set and assigns the label or value of the majority of those neighbors to the new point. In classification, the labels are discrete (e.g., "cat" or "dog"), and the algorithm assigns the class label that is most frequent among the k nearest neighbors. In regression, the labels are continuous, and the algorithm assigns the average of the values of the k nearest neighbors.
Main Difference
The main difference between k-means and k-NN is that k-means is an unsupervised algorithm that clusters data into groups, while k-NN is a supervised algorithm that assigns labels to data points based on their proximity to other labeled points. In other words, k-means tries to find patterns in the data by grouping similar observations, while k-NN uses existing labels to make predictions about new data points.
Another difference between the two algorithms is that k-means requires the user to specify the number of clusters (k) in advance, while k-NN does not require any such specification. Instead, the value of k in k-NN is usually determined by cross-validation, where the performance of the algorithm is tested on a separate validation set.
K-means is a popular algorithm for clustering data in fields such as image analysis, market segmentation, and social network analysis. K-NN is commonly used in applications such as recommender systems, fraud detection, and image recognition.
Main Points
- K-means is an unsupervised clustering algorithm, while K-NN is a supervised algorithm used for classification or regression.
- K-means clusters data into groups, while K-NN assigns labels to data points based on their proximity to other labeled points.
- K-means requires the user to specify the number of clusters in advance, while K-NN does not require any such specification.
- K-means tries to find patterns in the data by clustering similar observations, while K-NN uses existing labels to make predictions about new data points.
- K-means is commonly used in fields such as image analysis, market segmentation, and social network analysis, while K-NN is commonly used in applications such as recommender systems, fraud detection, and image recognition.
Summary
In summary, K-means and K-nearest neighbors (K-NN) are both machine learning algorithms, but they have different applications and operate in distinct ways. K-means is an unsupervised clustering algorithm used for finding clusters in a set of data, while K-NN is a supervised algorithm used for classification or regression. The main difference between the two is that K-means tries to find patterns in the data by clustering similar observations, while K-NN uses existing labels to make predictions about new data points. Another difference is that K-means requires the user to specify the number of clusters in advance, while K-NN does not require any such specification. K-means is commonly used in fields such as image analysis, market segmentation, and social network analysis, while K-NN is commonly used in applications such as recommender systems, fraud detection, and image recognition.
End Notes:
I hope you like this article.
Happy Learning !!
About the Creator
Natural Ways to Clear Blackheads and Whiteheads
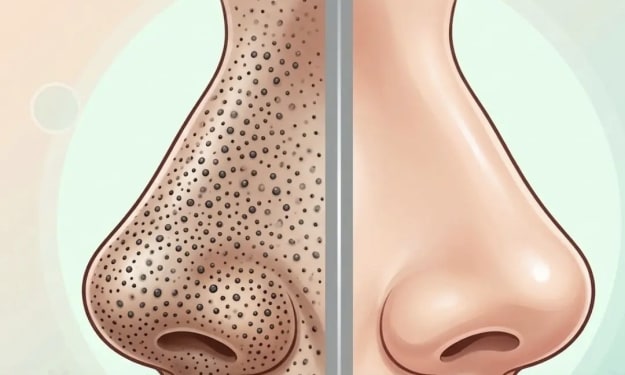
Blackheads and whiteheads are very common skin problems that affect people of all ages. They usually appear on the nose, chin, forehead, and sometimes on the cheeks. These small bumps form when the pores of the skin become clogged with oil, dead skin cells, and dirt. Blackheads appear dark because the clogged material inside the pore reacts with air and becomes oxidized, while whiteheads remain covered by skin, giving them a white or flesh-colored appearance.
By DigitalAddiabout 3 hours ago in Education



Comments
There are no comments for this story
Be the first to respond and start the conversation.