
Comparing Decision Tree and Random Forest: When to Use Each for Machine Learning
Decision Tree vs Random Forest

What is Decision Tree Algorithm
The Decision Tree Algorithm is a popular and powerful supervised machine learning technique used for solving both classification and regression problems. It works by constructing a tree-like model where each internal node represents a test on one or more features, and each leaf node represents a class label or a numerical value that represents the output of the model. The algorithm selects the best feature at each node to split the data into subsets that are as pure as possible in terms of the target variable.
The decision tree algorithm is widely used in various applications such as finance, marketing, engineering, and healthcare. It can handle both categorical and continuous data and can be used for binary and multi-class classification, as well as regression problems. Decision trees are easy to understand, interpret, and visualize, and can handle missing data and irrelevant features. However, decision trees are prone to overfitting, especially when the tree is too deep or too complex. Various techniques such as pruning, regularization, and ensemble methods can be used to address overfitting.
What is Random Forest Algorithm
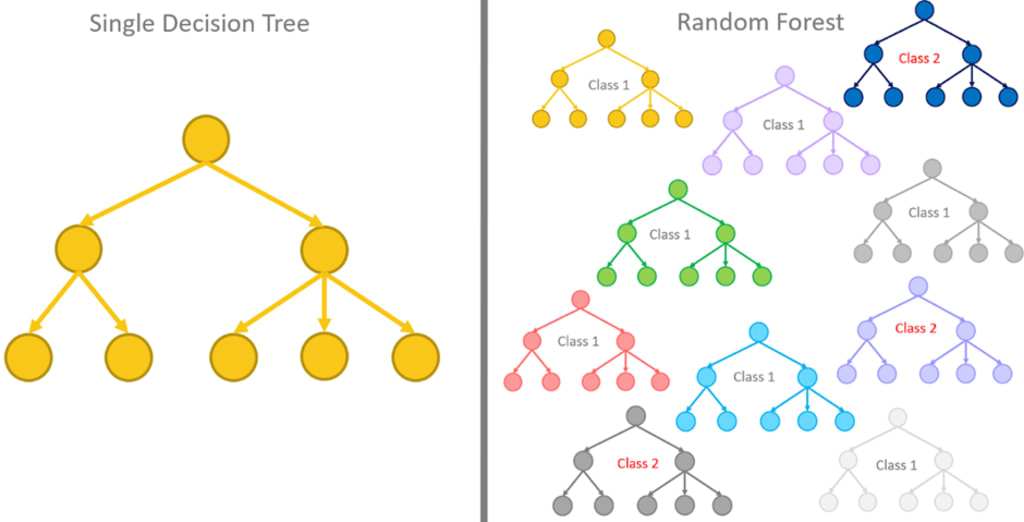
Random forest is an ensemble learning method in machine learning used for classification, regression, and other tasks that involve prediction. The method constructs a large number of decision trees on bootstrapped samples of the data, where each tree is trained on a random subset of the features. The final prediction is made by aggregating the predictions of all the trees in the forest.
Random forests have become popular because they provide high accuracy, are easy to use, and can handle large datasets with high-dimensional feature spaces. They are also resistant to overfitting, which can be a problem with individual decision trees.
In a random forest, each tree in the forest is grown using a different bootstrap sample of the data, and the split points for each tree are chosen from a random subset of the features. By using many trees, the random forest is able to capture the interactions and non-linearities in the data, while also reducing the variance of the model.
Random forests have many applications in real-world problems such as image classification, text classification, and bioinformatics. They are often used when accuracy is important, and when the data has complex relationships or high levels of noise.
Decision Tree vs Random Forest
The decision tree algorithm and random forest are both machine learning techniques used for solving classification and regression problems. While both methods use decision trees, there are some key differences between them.
The decision tree algorithm constructs a single tree by recursively partitioning the input space into smaller regions based on the value of one or more features. Each internal node in the tree corresponds to a test on one or more features, and each leaf node corresponds to a class label or a numerical value that represents the output of the model. The decision tree algorithm can handle both categorical and continuous data and can be used for both binary and multi-class classification, as well as regression problems. However, decision trees are prone to overfitting and may not generalize well to new data.
Random forests, on the other hand, are an ensemble learning method that combines multiple decision trees to improve performance and reduce overfitting. A random forest constructs a large number of decision trees on bootstrapped samples of the data, where each tree is trained on a random subset of the features. The final prediction is made by aggregating the predictions of all the trees in the forest. Random forests are effective in handling high-dimensional data and can reduce the variance of the model. However, random forests may be slower to train and may require more resources than a single decision tree.
Summary
In summary, decision tree algorithm and random forest are both machine learning techniques used for solving classification and regression problems. The decision tree algorithm constructs a single tree by recursively partitioning the input space into smaller regions based on the value of one or more features. Each internal node in the tree corresponds to a test on one or more features, and each leaf node corresponds to a class label or a numerical value that represents the output of the model. Decision trees are easy to understand, interpret, and visualize, but may suffer from overfitting.
Random forests are an ensemble learning method that combines multiple decision trees to improve performance and reduce overfitting. A random forest constructs a large number of decision trees on bootstrapped samples of the data, where each tree is trained on a random subset of the features. The final prediction is made by aggregating the predictions of all the trees in the forest. Random forests are effective in handling high-dimensional data and can reduce the variance of the model, but may be slower to train and require more resources than a single decision tree.
The choice between decision tree algorithm and random forest depends on the specific problem and the trade-offs between performance, interpretability, and computational resources. Decision trees are simpler to understand and interpret, but may suffer from overfitting. Random forests are more complex, but can improve performance and reduce overfitting.
About the Creator
Cutting for Impact: How Film Editing Shapes Powerful Stories Behind the Scenes
When audiences watch a great film, they rarely think about the countless decisions made in the editing room. Performances feel seamless, scenes flow naturally, and emotions rise at precisely the right moments. Yet behind this smooth experience lies a complex creative process. Film editing is often called the invisible art because, when done well, it goes unnoticed. However, its influence on storytelling is profound and far-reaching.
By Nigel Sinclair6 days ago in Education
Beyond the Protein: Mastering Wine Pairings by Understanding the Sauce
When planning a remarkable dinner, many hosts instinctively choose the wine based on the main protein. They assume red wine belongs with beef and white wine suits chicken or fish. However, this traditional rule often oversimplifies the art of pairing. Because sauces concentrate seasoning, texture, and aroma, they define the dish’s personality more than the protein itself. Therefore, if you want a truly elevated dining experience, you should evaluate the sauce before selecting the wine.
By Joel Barjenbruch4 days ago in Education



Comments
There are no comments for this story
Be the first to respond and start the conversation.