
Choosing the Right Expression for Join Operations in Spark SQL: A Comparison of String Expressions, Column Object Expressions, and Spark SQL Expressions"
How important the join operation "Comparing String, Column Object, and Spark SQL Expressions for Efficient and Readable Join Operations in Spark SQL"


Joins are important in Spark SQL because they allow you to combine data from two or more tables into a single result set, enabling you to gain a more comprehensive understanding of the data and create more complex analytics and reports.
There are several types of joins in Spark SQL, including:
Inner join: Returns only the rows that have matching values in both tables.
Left outer join: Returns all the rows from the left table and the matching rows from the right table.
Right outer join: Returns all the rows from the right table and the matching rows from the left table.
Full outer join: Returns all the rows from both tables, including the non-matching rows.
The efficiency of joins in Spark SQL can be optimized in several ways, including:
Broadcasting small datasets: If one of the tables being joined is small enough, it can be broadcast to all worker nodes in the cluster to reduce the amount of data that needs to be shuffled between nodes.
Partitioning the data: By partitioning the data in the tables being joined, Spark SQL can minimize the amount of data shuffling required, which can significantly improve performance.
Using indexing: Indexing the data in the tables can also improve the efficiency of joins by reducing the amount of data that needs to be processed.
Caching: Caching the data in memory can speed up repeated join operations and reduce the time required to perform the join.
In Spark SQL, you can perform join operations using the join method in the DataFrame API & you can perform join operations using different expressions such as
-String expressions,
-column object expressions,
-Spark SQL expressions.
The choice of expression depends on the specific requirements of the query and the user’s preference.
Here’s a comparison of these three expressions:
String Expression: String expressions are convenient and flexible, as they allow you to write join conditions as plain text. However, they may not be as readable as column object expressions and may require additional parsing and processing.
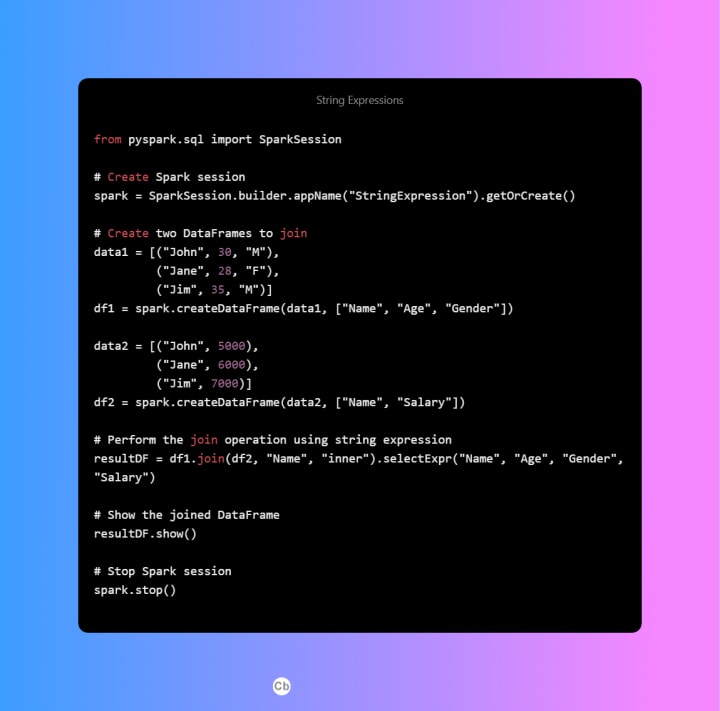
Column Object Expression: Column object expressions are recommended for join operations in Spark SQL, as they provide a clean and readable syntax for joining tables based on common columns. They are efficient and well supported by Spark SQL.
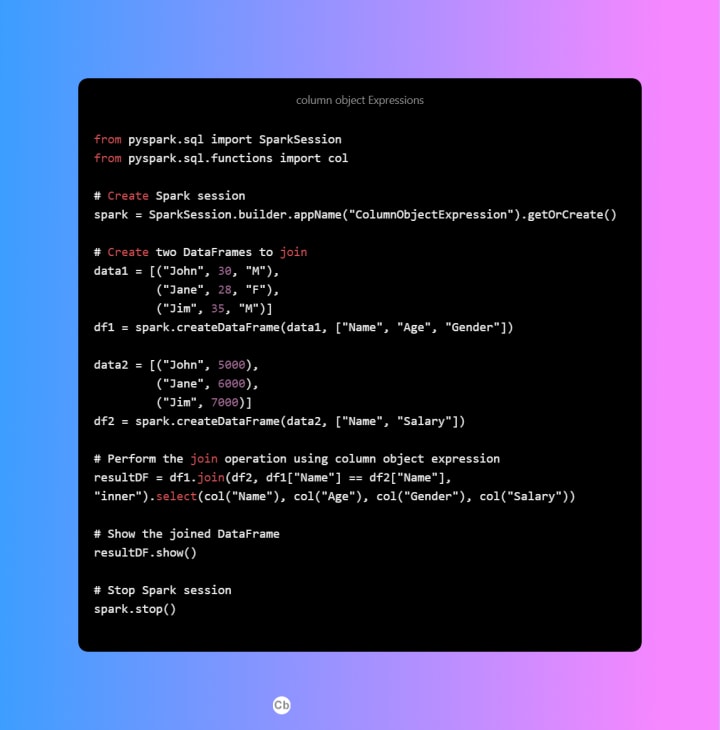
Spark SQL Expression: Spark SQL expressions are powerful, as they allow you to perform complex operations using Spark SQL functions. However, they may not be as readable as column object expressions and may require additional parsing and processing.
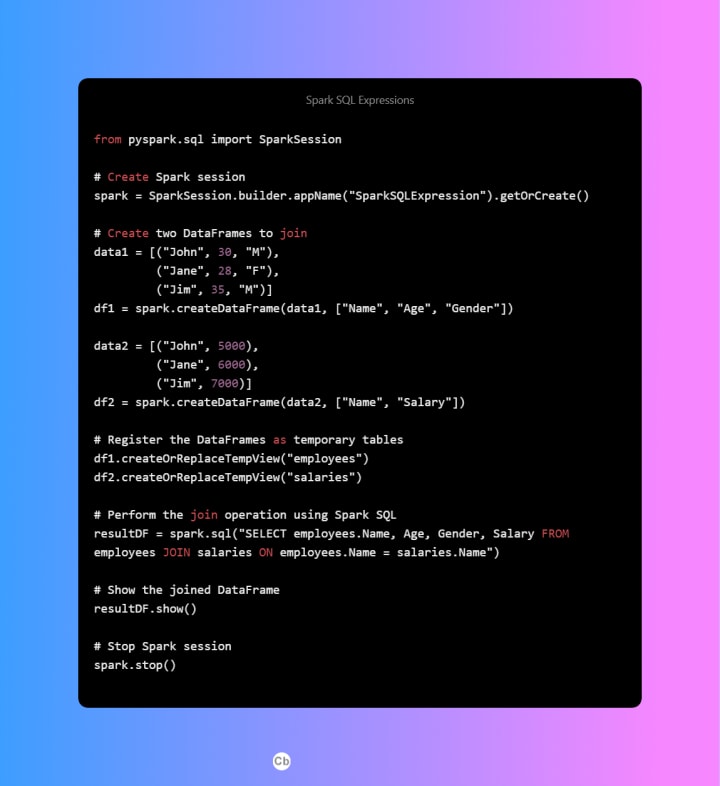
In real-time scenarios, the choice of expression for performing join operations in Spark SQL depends on various factors such as:
Data size and complexity: If the data size and complexity are high, a column object expression may be preferred as it provides a clean and readable syntax while being efficient and well supported by Spark SQL.
Performance: Performance is a critical factor in real-time scenarios, and the choice of expression should be based on the query’s performance requirements. In general, column object expressions are preferred for join operations, as they are efficient and well supported by Spark SQL.
Readability: The readability of the code is also an important factor in real-time scenarios, as it affects the maintainability and debug-ability of the code. Column object expressions are recommended for join operations, as they provide a clean and readable syntax.
Flexibility: In some cases, the join condition may require complex operations or calculations. In such cases, Spark SQL expressions may be preferred as they allow you to perform complex operations using Spark SQL functions.
Customization: String expressions are preferred in scenarios where customization is required, as they allow you to write join conditions as plain text.
In conclusion, the choice of expression for performing join operations in Spark SQL depends on various factors such as data size, complexity, performance, readability, flexibility, and customization.
Data Frame API
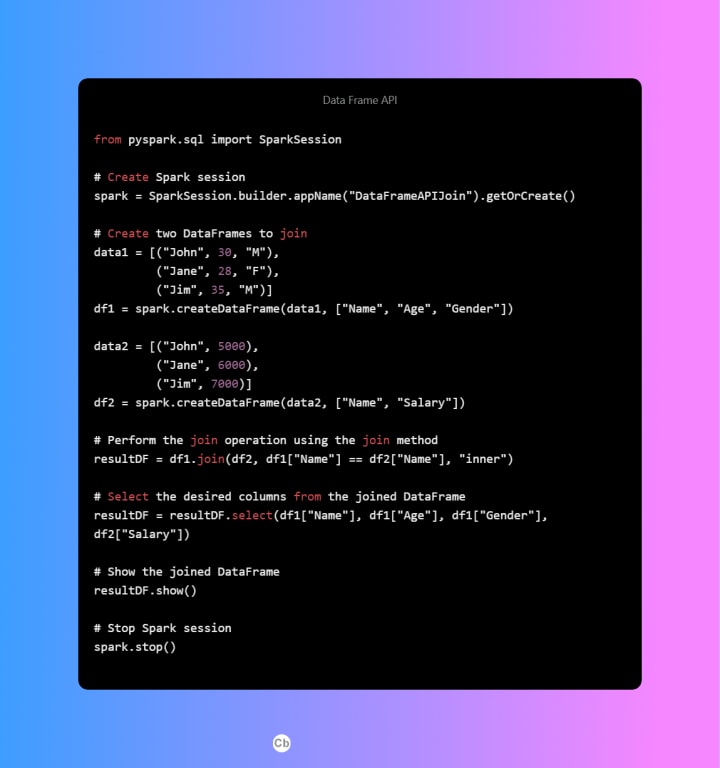
The attached images indeed show sample programs for 4 types of join operations with the same data.
About the Creator
Varun Pandian
"I am a data engineer with a passion for using data to drive business decisions and solve complex problems. With a strong foundation in computer science and programming, and experience with technologies such as SQL, Python, and Hadoop
Keep reading
More stories from Varun Pandian and writers in Education and other communities.
What is ? -Why ? - How ? - Optimization help full in Big Data
Optimization is the process of making something, such as a system or process, perform as efficiently and effectively as possible. It involves finding the best solution among a set of possible solutions, by adjusting various parameters and variables. Optimization is important because it helps to improve the performance of a system, process or model, and can also help to reduce costs, increase efficiency and improve the quality of the results.
By Varun Pandian3 years ago in Education
Best Laptop for Digital Art
In the vibrant world of digital art, the right laptop can be your greatest creative ally. Whether you're sketching breathtaking illustrations, designing compelling graphics, or animating entire worlds, you need more than just a machine you need a digital canvas that brings your ideas to life.
By Home Care Ranksabout 13 hours ago in Education
5 signs you're a good driver
As one of the agency’s best employees, you’ve been selected as a finalist to potentially take on a new top-secret mission. You've already shown your aptitude for surveillance and disguise, but the agency is looking to test one last critical skill: how well you can drive. To prove yourself, you’ll need to complete a series of complicated challenges behind the wheel. As the test begins, you notice that the distances between yourself and the cars around you are being meticulously monitored. One of the most widely recommended strategies when it comes to safe driving
By Munesh Yadav3 days ago in Education




Comments
There are no comments for this story
Be the first to respond and start the conversation.