
Secret recipe to cook a “better” machine learning model
The data science community is is expected to grow USD 96.7 billion by 2025. What are you doing about it?
It is no myth that Data Science and Machine learning has seen an exponential growth over the past few decades. According to this,
The global machine learning market size was accounted for USD 6.9 billion in 2018 and is anticipated to value USD 96.7 billion until 2025.
USD 96.7 billion, let that sink in for a moment.

The question arises, what exactly is machine learning? Well, in simple terms, it is like putting a child through school. Give your machine learning algorithm a big chunk of data and the algorithm will simply learn the complex relationships among the various components of your data. Sounds simple, right? Not so much!
If it were easy, everyone would do it. The “hard” is what makes anything great.
~ Jimmy Dugan (A League of their own)
There are some defined machine learning algorithm that expects data to be given to them and output a machine learning model ‘trained’ on this data. You can use this model and make future predictions for similar data. There are a number of machine learning models, that you can choose from depending upon the complexity of your problem. There comes a phase when you have to “tune” your model so that it can be generalized but not so general that it is basically dumb.
The reason I am telling all this is because the learning of your model directly depends upon your machine learning algorithm. The better the algorithm, the better is the model and hence the better the performance. Well, this is right to some extent. If the model performance depended only on the machine learning algorithm, you could just build the most complex model you know, such as an Artificial Neural network and be done with it. That is actually what most people try to do. And since, most of the people do this, how do you make sure your model stands out of the crowd?
So, the question still remains, how to build a better machine learning model? Well, as they say, a great student comes from a great teacher. Question yourself this, who is the teacher to your machine learning model? The Data. And who are you? The Data Scientist. My point is, to be better at machine learning model, you need to be an out-of-the-box thinker data scientist. It basically implies, bring out the scientist in you, and experiment as much as you can on your data. The better the quality of your data, the better the algorithm, the better the model!
This amazing process of drawing out more features from the existing ones is called Feature Engineering!
Let me give you a simple high school reason as to why you should experiment on your data. I’m sure most of you people already know this. Hydrogen is flammable and oxygen is required to keep the fire, but combine 2 atoms of hydrogen and 1 atom of oxygen, you get water, a molecule that extinguishes the fire. So you see, just by combining 2 different components, we get another component which has entirely different properties. Try to expand this argument to the components in your data.
It is time for an example, the legendary Titanic survival prediction competition on Kaggle. This is how I approached the problem, and uncovered some missing facts that you might’ve missed!
To give you a brief introduction to the problem, this is how our beloved data looks like,
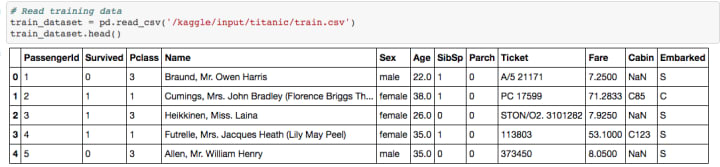
You are given some features about every person onboard the Titanic, and whether they survived the sinking or not. Features include name, sex, number of sibling, number of parents and children, ticket number, fare, cabin class and embarked category. You need predict whether a given person would survive or not. The first instinct every data scientist has to drop the irrelevant columns, which makes sense because you don’t want to input some data into algorithm from which there is no learning. So, the first thought is to drop PassengerId, Name and Ticket. But hold your horses, let us take a closer look for a moment.
Digging a bit deeper in Name.
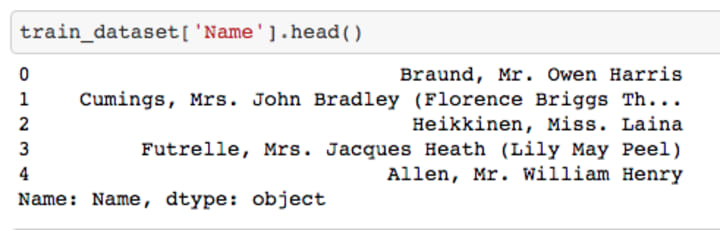
The names are associated with titles such as Mr, Mrs., Miss etc. Separating the title from the name,
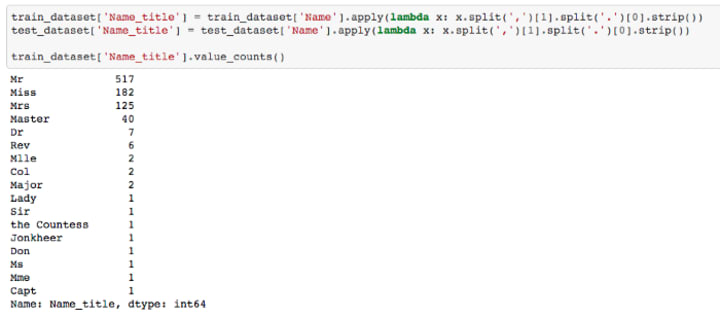
Whoa! We’ve got a good mix of people onboard on the Titanic. If you checked whether the higher title people survived or not, surprise surprise! They did. The people with a higher title are more likely to survive the sinking Titanic.
Digging a bit deeper in Ticket.
The ticket column had some numeric fields and some character fields. So, I differentiated the numeric ones and the character ones.
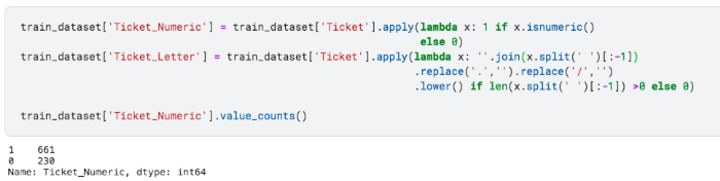
Checking the survival ratio for people with numeric tickets
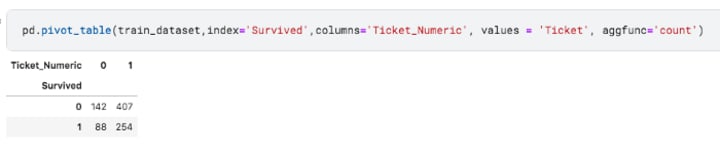
It doesn’t explain much, but it is worth experimenting. Looks like people with numeric ticket has a higher chance at survival but if you see, approximately 3 times of the people had numeric tickets so this might not be a fair assumption.
The next step after removing the non required fields would be to check for null values and drop the columns with a higher null value count.
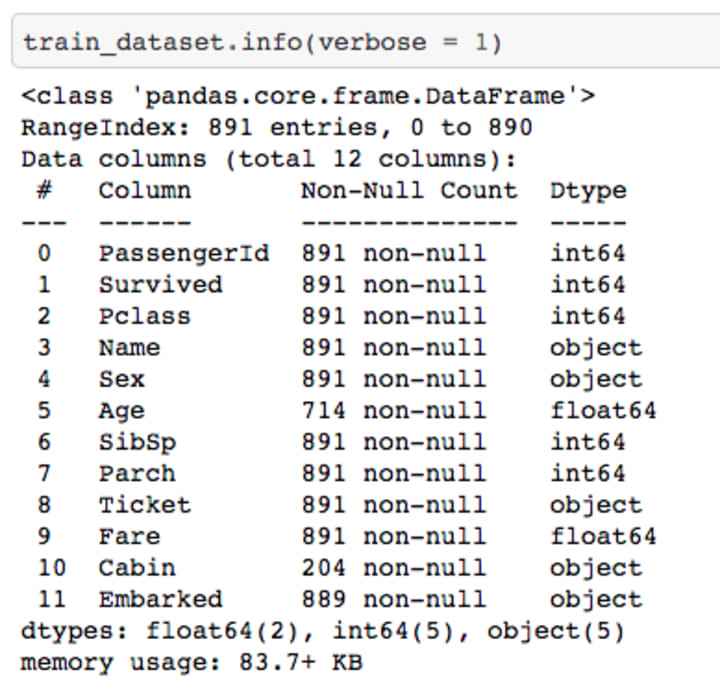
Cabin, has only 204 values out of 891, which means around 75% of the values are null. The first instinct would tell you to drop this column. But, allow the scientist to experiment on the data!
Digging a bit deeper in Cabin
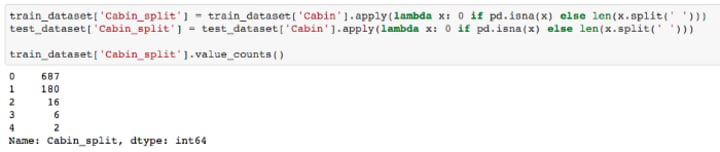
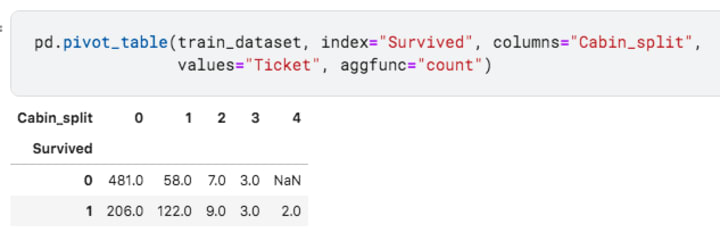
As you can observe, people with a higher cabin number had a higher chance of survival! Now, only the rich people could’ve afforded the cabin. Does that mean the rich people had a higher chance at survival?
Some other conclusions from the Titanic dataset
PClass
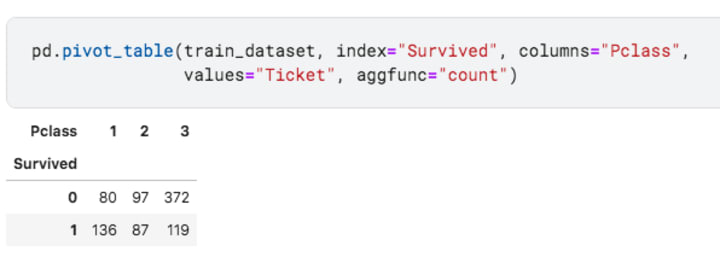
First class survival ratio is quite higher and greater then 1 actually. This does mean that the rich folks had a higher chance at surviving the sinking titanic. We’ve gotta earn more money, man!
Sex
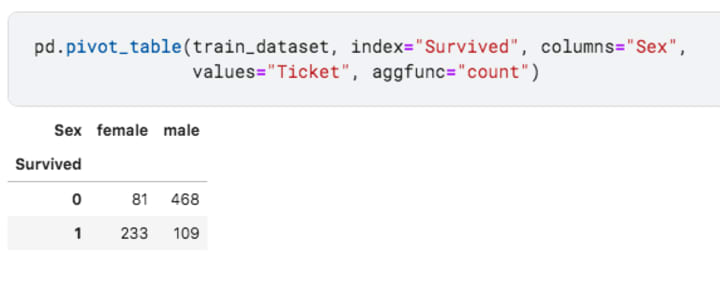
Well, this was fairly expected and I’m sure most of us already explored this. The survival ratio for females is much higher than the males.
So, if you were a rich female person with a distinguished title, you had the best chance at surviving the sinking Titanic.
You see the power of feature engineering, right? I know for a fact that the highest rated and best performing models in any competition, always and always have a unique and interesting feature engineering. They might not use the most advanced models but they always experiment on their data.
Check out my complete implementation here.
Keep experimenting, my fellow “data scientist”!
About the Creator
Keep reading
More stories from writers in 01 and other communities.
Daniel Raphael Dreamporting Review: What to Know Before You Join
Personal development programs often promise clarity, growth, and transformation—but the experience can vary widely depending on the approach and the individual. Dreamporting, founded by Daniel Raphael, is one such program that attracts curiosity, discussion, and mixed opinions. Rooted in mindfulness and consciousness-based development, it stands apart from more conventional coaching systems.
By Jeffrey D. Gross MD5 days ago in 01
Candace Owens pushes theory Charlie Kirk was 'time traveller' who went to 'X-Men school'
In a recent episode of her podcast, Candace Owens said Charlie Kirk told her he was a “time traveler” who was sent to “X-Men school,” and alleged he was monitored since childhood.
By Dena Falken Esqabout 19 hours ago in 01




Comments
There are no comments for this story
Be the first to respond and start the conversation.