
Did DeepSeek Copy OpenAI?
Was DeepSeek a copy of OpenAI?


In the last couple of days, there’s been controversy surrounding DeepSeek, a Chinese AI startup, and its alleged use of OpenAI’s proprietary models.
The issue came after DeepSeek released two models, DeepSeek-V3 and DeepSeek-R1, which achieve performance comparable to OpenAI’s counterparts at significantly lower costs.
OpenAI has accused DeepSeek of improperly using its data to train a competing AI model. This accusation has sparked a heated debate about intellectual property rights in the AI sector and the ethics of model distillation.
Model distillation, also known as knowledge distillation, is a machine learning technique used to transfer knowledge from a large, complex model (the “teacher”) to a smaller, more efficient model (the “student”).
A distilled model is basically a smaller model that performs similarly to the larger one but requires fewer computational resources.
If you’re interested in knowing how an OpenAI model is distilled, check out this documentation.
What Exactly Was Copied?
In the fall of 2024, Microsoft’s security researchers observed a group believed to be connected to DeepSeek extracting large amounts of data from OpenAI’s API.
This activity raised concerns that DeepSeek was using distillation to replicate OpenAI’s models without authorization. The excessive data retrieval was seen as a violation of OpenAI’s terms and conditions, which restrict the use of its API for developing competing models.
According to Mark Chen, Chief Research Officer at OpenAI, DeepSeek managed to independently find some of the core ideas OpenAI had used to build its o1 reasoning model.
Congrats to DeepSeek on producing an o1-level reasoning model! Their research paper demonstrates that they’ve independently found some of the core ideas that we did on our way to o1.
Chen noted that the reaction to DeepSeek, which caused NVIDIA to lose $650 billion in market value in a single day, might have been overblown.
However, I think the external response has been somewhat overblown, especially in narratives around cost. One implication of having two paradigms (pre-training and reasoning) is that we can optimize for a capability over two axes instead of one, which leads to lower costs. — Mark Chen
While OpenAI has not disclosed the full details of the evidence, it has confirmed that there is substantial evidence indicating DeepSeek used distillation techniques to train its models.
In response to these findings, OpenAI and Microsoft blocked access to OpenAI’s API for accounts suspected of being linked to DeepSeek. This move is part of a broader effort by the U.S. AI companies to safeguard their intellectual property and prevent unauthorized use of their models.
The controversy has also led to national security concerns, with the White House reviewing the implications of such practices on the U.S. AI industry.
Model Distillation is Legal
Model distillation itself is not inherently illegal. It is a widely used technique in the AI industry to create more efficient models by transferring knowledge from a larger model to a smaller one.
Take the Stanford Alpaca model as an example. Alpaca is a language model fine-tuned using supervised learning from a LLaMA 7B model on 52K instruction-following demonstrations generated from OpenAI’s text-davinci-003.
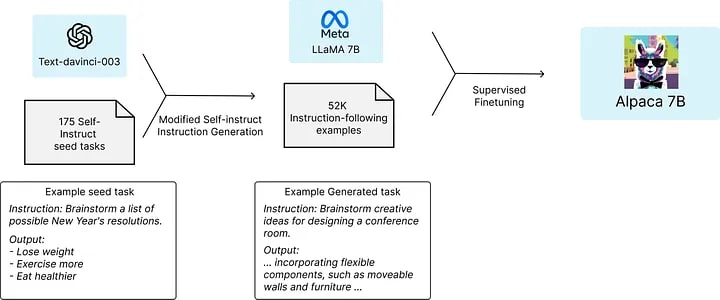
The data generation process results in 52K unique instructions and the corresponding outputs, which cost less than $500 using the OpenAI API.
It demonstrates how distillation can be used to create smaller, more affordable models that still perform well.
In fact, if you read DeepSeek’s whitepaper, DeepSeek R-1 is a distilled model from Qwen (Qwen, 2024b) and Llama (AI@Meta, 2024).
To support the research community, we open-source DeepSeek-R1-Zero, DeepSeek-R1, and six dense models (1.5B, 7B, 8B, 14B, 32B, 70B) distilled from DeepSeek-R1 based on Qwen and Llama.
Based on DeepSeek’s findings, it appears that this straightforward distillation method significantly enhances the reasoning abilities of smaller models.
The controversy stems from allegations that DeepSeek used OpenAI’s model outputs to fine-tune their own models, which may be against OpenAI’s terms of service. This raises questions about fair use, data ownership, and the competitive landscape in the AI industry.
Running DeepSeek API Requires OpenAI Libraries
To use DeepSeek’s API, you need to run ‘npm install openai.’
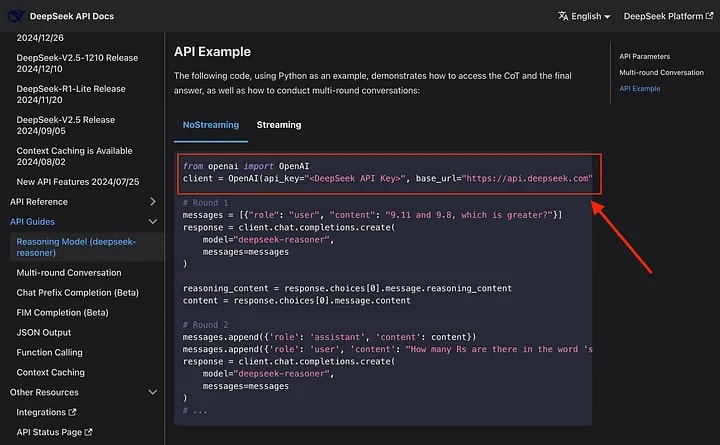
Yep, you read that right. DeepSeek works with OpenAI’s client libraries! This is possible because DeepSeek’s REST API is fully compatible with OpenAI’s API.
This is hilariously genius.
- DeepSeek avoided spending weeks building Node.js and Python client libraries by reusing OpenAI’s code.
- Developers using OpenAI can easily try or switch to DeepSeek by just changing the base URL and API key.
- If DeepSeek ever needs to make changes, they can simply fork the library and replace OpenAI with DeepSeek.
As a developer, this is actually a good thing, and I don’t see it as a huge problem because this is a common practice for LLM providers and aggregators. OpenRouter, Ollama, DeepInfra, and a bunch of others do this too.
Speaking of API access, according to Deepseek, you can use R1’s API at a fraction of what you’d pay OpenAI.
- 💰 $0.14 / million input tokens (cache hit)
- 💰 $0.55 / million input tokens (cache miss)
- 💰 $2.19 / million output tokens
The output token is almost 30 times cheaper than the $60 per million output tokens for o1. That’s a huge cut in terms of cost for companies running large-scale AI operations.
Check out this visual comparison of DeepSeek’s R1 to OpenAI’s models.
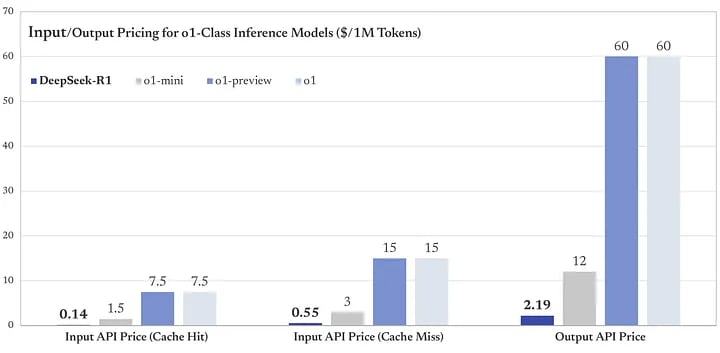
Switching to the R-1 API would mean a huge savings. You can learn more about DeepSeek’s API access here.
Final Thoughts
DeepSeek was barely known outside research circles until last month when it launched its v3 model. Since then, it has caused AI stocks to drop and even been called a “competitor” by OpenAI’s CEO. It’s unclear how things will play out for DeepSeek in the coming months, but it has definitely caught the attention of both the public and major AI labs.
Ironically, it feels weird that OpenAI is accusing DeepSeek of IP theft, given their own history of copyright infringement. OpenAI gathered massive amounts of data from the internet to train its models, including copyrighted material, without seeking permission. This has led to lawsuits from authors like George R.R. Martin and Elon Musk (regarding Twitter data).
OpenAI may become even more closed off as a result. Do you remember the incident when Musk shut down free API access to X (formerly Twitter) due to data being stolen? Although there’s a thin chance that OpenAI will do the same, it’s not unlikely to happen.
About the Creator
Keep reading
More stories from Souad Cheraif and writers in Lifehack and other communities.
Benefits of Remote Working for Employees and Employers
Remote working has transformed the traditional workplace, offering a new model that benefits both employees and employers. With technology bridging the gap between home and office, businesses are reaping significant advantages, while employees enjoy flexibility and improved work-life balance. In this article, we explore the various benefits of remote working and how this shift is redefining success in today’s dynamic work environment.
By Souad Cheraif12 months ago in Lifehack
Ludacris and Nelly draw backlash over bookings at MAGA-coded music festival
Ludacris and Nelly headlining a mostly right-wing event is good for them. It’s also great for the genre of hip hop. The two rap veterans have showcased their talents on other stages. Why can’t they perform for mostly MAGA folks and grab that bag?
By Skyler Saunders4 days ago in Beat




Comments
There are no comments for this story
Be the first to respond and start the conversation.