
Top 5 alternatives of ChatGPT
Comparing the features and performance of GPT-2, BERT, RoBERTa, ALBERT, and ChatGPT for natural language processing tasks


Here are the top 5 alternates of ChatGPT
- BERT (Bidirectional Encoder Representations from Transformers)
- GPT-2 (Generative Pre-trained Transformer 2)
- XLNet
- RoBERTa (Robustly Optimized BERT)
- ALBERT (A Lite BERT)
BERT (Bidirectional Encoder Representations from Transformers)
BERT (Bidirectional Encoder Representations from Transformers) is a transformer-based neural network model developed by Google in 2018. BERT is trained on a large corpus of text data using a technique called unsupervised pre-training, which allows it to learn the underlying relationships between words and phrases in a given language. This pre-training allows BERT to then be fine-tuned on specific tasks such as question answering and sentiment analysis with a smaller dataset. BERT has achieved state-of-the-art results on a wide range of natural language understanding tasks and is widely used in industry and academia.
Advantages
- Pre-training: BERT is pre-trained on a large corpus of text data, allowing it to learn the underlying relationships between words and phrases in a given language. This pre-training allows BERT to then be fine-tuned on specific tasks with a smaller dataset.
- Bidirectional: BERT uses a bidirectional transformer architecture, which allows it to take into account the context of a word in both the left and right context. This improves its ability to understand the meaning of a word in a sentence.
- Fine-tuning: BERT can be fine-tuned on a wide range of natural language understanding tasks such as question answering, sentiment analysis, and named entity recognition.
Disadvantages
- Computationally intensive: BERT is a large model, with millions of parameters, which makes it computationally intensive to train and deploy.
- Limited context: BERT is pre-trained on a large corpus of text data but the context it has seen during pre-training is limited. It may not have seen certain types of language, making it less effective on those types of tasks.
- Limited to text-based inputs: BERT is designed to process text data, and is not well-suited for processing other types of data such as images or audio.
GPT-2 (Generative Pre-trained Transformer 2)
GPT-2 (Generative Pre-trained Transformer 2) is a transformer-based neural network model developed by OpenAI in 2018. It is an extension of GPT (Generative Pre-trained Transformer) and it is pre-trained on a large corpus of text data using a technique called unsupervised pre-training, which allows it to learn the underlying relationships between words and phrases in a given language. This pre-training allows GPT-2 to then be fine-tuned on specific tasks such as language translation and text summarization with a smaller dataset. GPT-2 is known for its ability to generate human-like text and it is capable of completing a given prompt in a way that is difficult to distinguish from text written by a human. However, since it was also trained on large amounts of web pages, it may generate text that is biased or false.
Advantages
- Generative: GPT-2 is a generative model, which means it can generate new text based on a given prompt. This allows it to be used for a wide range of tasks such as text completion, summarization, and translation.
- Pre-training: GPT-2 is pre-trained on a large corpus of text data, which allows it to learn the underlying relationships between words and phrases in a given language. This pre-training allows GPT-2 to then be fine-tuned on specific tasks with a smaller dataset.
- Human-like text generation: GPT-2 is known for its ability to generate human-like text, which makes it useful for tasks such as chatbots and customer service.
Disadvantages
- Bias: GPT-2 is trained on a large corpus of text data from the internet, which can include biased or false information. This can lead to the model generating text that is also biased or contains false information.
- Lack of control over generated text: GPT-2 generates text based on patterns it has learned from its training data, which can lead to the model generating text that is not appropriate or relevant to a given prompt or task.
- Large computational resources: GPT-2 is a large model and requires significant computational resources to train and use, which can be a limitation for some organizations.
XLNet
XLNet is a transformer-based neural network model developed by Google AI in 2019. It is an extension of the BERT model and it is pre-trained on a large corpus of text data using a technique called permutation-based training, which allows it to learn the underlying relationships between words and phrases in a given language in a more efficient and effective way than BERT. XLNet is designed to overcome some of the limitations of the BERT model, such as its lack of ability to use context from all directions in the input text.
XLNet is trained to maximize the likelihood of the entire input sequence, rather than the likelihood of a specific masked word like BERT does. This allows XLNet to better handle tasks that depend on the context from the entire input sequence, such as text generation, machine translation and text summarization. Additionally, XLNet has been shown to outperform BERT on a wide range of natural language understanding tasks, such as question answering, sentiment analysis and named entity recognition.
However, as XLNet is a relatively new model, it is not as widely used as BERT yet and it requires more computational resources to train and use.
Advantages
- Efficient Training: Permutation-based training allows for more efficient and effective learning of underlying relationships between words and phrases in a given language,
- Contextual generation: Can use context from all directions in the input text which allows XLNet to better handle tasks that depend on context from the entire input sequence, such as text generation, machine translation, and text summarization
- Performance: XLNet has been shown to outperform BERT on a wide range of natural language understanding tasks such as question answering, sentiment analysis, and named entity recognition.
Disadvantages
- Computational resources: XLNet is a large model and requires significant computational resources to train and use, which can be a limitation for some organizations.
- Limited adoption: XLNet is relatively new compared to other models and it is not as widely adopted in industry and academia as BERT and GPT-2.
- Limited multi-language support: XLNet is primarily trained on English text, and its performance on other languages is not as good as BERT and GPT-2.
RoBERTa (Robustly Optimized BERT)
RoBERTa (Robustly Optimized BERT) is a transformer-based neural network model developed by Facebook AI in 2019. It is an extension of the BERT model and it is pre-trained on a larger corpus of text data than BERT, with a longer training schedule and a more robust training procedure. RoBERTa is designed to overcome some of the limitations of the BERT model and improve its performance on a wide range of natural language understanding tasks.
RoBERTa is trained with a larger batch size, a longer training schedule, and on a larger corpus of text data than BERT. Additionally, RoBERTa removes the next sentence prediction objective used in BERT, which allows the model to focus more on language understanding tasks. RoBERTa also uses dynamic masking, where the model can attend to all positions in the input text, rather than just a masked subset.
RoBERTa has been shown to outperform BERT on a wide range of natural language understanding tasks, such as question answering, sentiment analysis, and named entity recognition. RoBERTa is also fine-tuned on a wide range of natural language processing tasks, making it useful for a variety of applications.
However, as RoBERTa is a relatively new model, it is not as widely used as BERT yet and it requires more computational resources to train and use.
Advantages
- Improved performance: RoBERTa is trained with a larger batch size, a longer training schedule, and on a larger corpus of text data than BERT, which improves its performance on a wide range of natural language understanding tasks such as question answering, sentiment analysis, and named entity recognition.
- Dynamic masking: RoBERTa uses dynamic masking, where the model can attend to all positions in the input text, rather than just a masked subset, which makes it more robust and accurate.
- Multi-language support: RoBERTa is pre-trained on a large corpus of text data from various languages and it can be fine-tuned on a wide range of natural language processing tasks, making it useful for a variety of applications.
Disadvantages
- Computational resources: RoBERTa is a large model and requires significant computational resources to train and use, which can be a limitation for some organizations.
- Limited adoption: RoBERTa is relatively new compared to other models and it is not as widely adopted in industry and academia as BERT and GPT-2.
- Limited multi-language support: RoBERTa is primarily trained on English text, and its performance on other languages is not as good as BERT and GPT-2.
ALBERT (A Lite BERT)
ALBERT (A Lite BERT) is a transformer-based neural network model developed by Google in 2019. It is an extension of the BERT model and it is designed to reduce the number of parameters while maintaining or even improving the performance of BERT. ALBERT reduces the number of parameters by factorizing the embedding parameter matrix into two smaller matrices, and by sharing parameters across the layers.
ALBERT is pre-trained on a large corpus of text data, and it can be fine-tuned on a wide range of natural language understanding tasks. ALBERT has been shown to outperform BERT on some natural language understanding tasks, such as question answering and sentiment analysis, while having fewer parameters.
ALBERT is also trained with a technique called "intermediate-task training" which enables the model to learn from a wider range of tasks during pre-training, making it more versatile.
However, as ALBERT is a relatively new model, it is not as widely used as BERT yet and it requires more computational resources to train and use. It also requires fine-tuning on specific tasks, and this process may require a significant amount of computational resources and time. Additionally, the input data needs to be pre-processed in a specific format before being fed to the model which can be a limitation.
Advantages
- Fewer parameters: ALBERT is designed to reduce the number of parameters while maintaining or even improving the performance of BERT, which makes it more efficient and easier to use.
- Improved performance: ALBERT has been shown to outperform BERT on some natural language understanding tasks, such as question answering and sentiment analysis, while having fewer parameters.
- Intermediate-task training: ALBERT is trained with a technique called "intermediate-task training" which enables the model to learn from a wider range of tasks during pre-training, making it more versatile.
Disadvantages
- Computational resources: ALBERT is a large model and requires significant computational resources to train and use, which can be a limitation for some organizations.
- Limited adoption: ALBERT is relatively new compared to other models and it is not as widely adopted in industry and academia as BERT and GPT-2.
- Fine-tuning and pre-processing: ALBERT requires fine-tuning on specific tasks, and this process may require a significant amount of computational resources and time. Additionally, the input data needs to be pre-processed in a specific format before being fed to the model which can be a limitation.
Feature comparison with ChatGPT
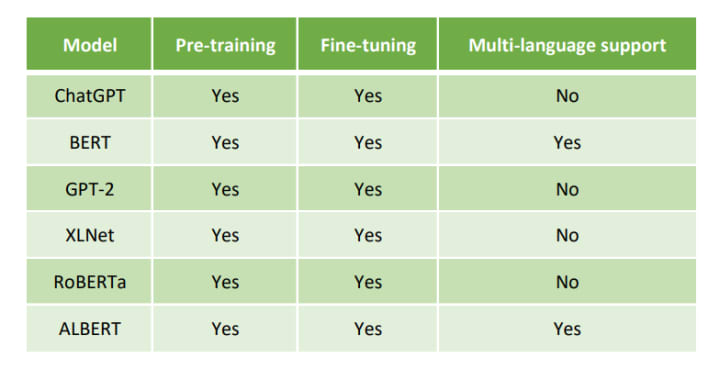
Please note that GPT-3 which is an extension of GPT-2 is also a good alternative and it has multi-language support.
In conclusion, GPT-2, BERT, RoBERTa, ALBERT, and ChatGPT are all large pre-trained transformer-based neural network models developed by OpenAI, Google and others. Each model has its own unique features and advantages, and they are suitable for different types of natural language processing tasks.
GPT-2 is known for its ability to generate human-like text and its large-scale pre-training. BERT is known for its ability to perform well on a wide range of natural language understanding tasks, and it is widely adopted in industry and academia. RoBERTa is an improved version of BERT that is trained on more data and with a different training technique, resulting in better performance on some natural language understanding tasks. ALBERT is designed to reduce the number of parameters while maintaining or even improving the performance of BERT, making it more efficient and easier to use. ChatGPT is known for its ability to generate human-like text and its large-scale pre-training.
When choosing a model for a specific task, it is important to consider the size of the model, the computational resources required, the performance on the specific task, and the availability of pre-trained weights and fine-tuning scripts.
About the Creator
Keep reading
More stories from writers in Futurism and other communities.
About Binding Prometheus
I want to start actively advocating on behalf of my own work, and the most valuable part of my canon is, without a doubt, Binding Prometheus, the play I have been working on since 2019 and only finished in 2023 as part of my MA. The play itself is an amalgamation of a million different inspirations. On one end, it evokes the Ancient Greek myth-play, deriving its own title from the earliest extant work of Western drama we have, Aeschylus’s Prometheus Bound. On the other end, it borrows significantly from the sci-fi bulwarks from over the years, namely Mary Shelley’s Frankenstein and Karel Capek’s Rossum’s Universal Robots. The play could be an episode of Black Mirror, I fear. I don’t know. I’ve only ever seen one episode of Black Mirror.
By Steven Christopher McKnight20 days ago in Futurism
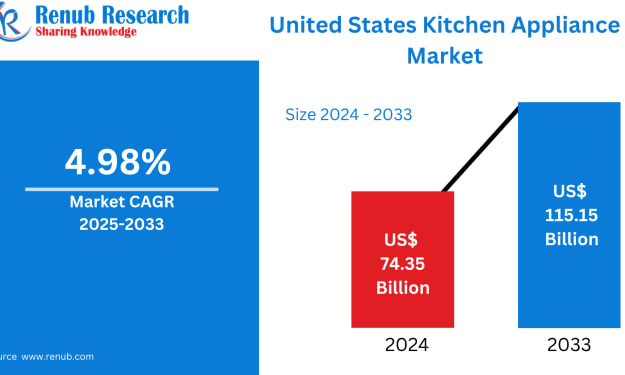
United States Kitchen Appliance Market Size and Forecast 2025–2033
The United States kitchen appliance market is entering a defining decade shaped by innovation, sustainability, and evolving consumer lifestyles. According to Renub Research, the market is projected to reach US$ 115.15 billion by 2033, rising from US$ 74.35 billion in 2024, at a compound annual growth rate (CAGR) of 4.98% during 2025–2033.
By Marthan Sir5 days ago in Futurism



Comments
There are no comments for this story
Be the first to respond and start the conversation.