
Can GPT-4 be a Saviour in the Medical Field ?
GPT-4’s capabilities make it a suitable player to assist in healthcare. However, is it completely reliable?

While OpenAI capacities have advanced into all spaces imaginable, there's one field where LLMs, whenever used accurately, can have the most noteworthy effect by straightforwardly influencing lives — the clinical field. Recently, ChatGPT had even gotten every one of the three sections free from the US Clinical Permitting Assessment (USMLE) and we even perceived how ChatGPT helped save a wretched existence through precise clinical conclusion. Be that as it may, we have not seen a lot of reasonable applications in the clinical field. Does GPT-4 capacities make it a reasonable player in the clinical field?
Monstrous Potential
A paper delivered by OpenAI and Microsoft on the Capacities of GPT-4 on Clinical Test Issues was delivered in Spring, this year. In this exploration, GPT-4 have shown great language understanding and age capacities in medication. The review assesses GPT-4's presentation on clinical capability tests and benchmark datasets, despite the fact that the model wasn't particular for medication.
The specialists evaluate GPT-4's exhibition on true USMLE practice materials and MultiMedQA datasets. GPT-4 outperforms the USMLE disregarding score by 20, outflanking past models (counting GPT-3.5) and even models calibrated for clinical information. Furthermore, GPT-4 exhibits further developed likelihood alignment, inferring that it's better at foreseeing right responses. The concentrate additionally investigates how GPT-4 can make sense of clinical thinking, alter clarifications, and make speculative situations, exhibiting its true capacity for clinical instruction and practice. The discoveries feature GPT-4's capacities while recognizing difficulties connected with precision and security in certifiable applications.
In contrast with its more seasoned models, GPT-4 has gotten much better when tried on true clinical tests like USMLE. GPT-4 better by a bigger number of than 30 rate focuses when contrasted with GPT-3.5. While GPT-3.5 was drawing near to this passing score (60% of different decision inquiries to be right), GPT-4 passed the score by a tremendous number.
Arrangement and Wellbeing Set up
At the point when a prior rendition of GPT-4, alluded to as the base model, was contrasted and GPT-4, the previous had somewhat better execution by around 3-5% on a portion of the tests. This recommends that when the model was made more secure and better at adhering to directions, it could have lost some of its crude presentation. The analysts proposed that future work could zero in on tracking down ways of adjusting precision and wellbeing all the more successfully by refining the preparation cycle or by utilizing specific clinical information.
Where does Drug PaLM fit in?
The above research didn't contrast GPT-4 and models, for example, Prescription PaLM and Flan-PaLM 540B, as the models were not accessible for everybody to attempt at the hour of study.
Google as of late sent off their multimodal medical services LLM with Drug PaLMM - a huge multimodal generative model that encodes and deciphers biomedical information. Its capacities are definitely further developed than GPT-4 thinking about how it can deal with different sorts of clinical information, for example, clinical language, clinical pictures, genomics and even plays out many assignments. The model can sum up to new clinical assignments and perform multimodal thinking without explicit preparation. It can definitively perceive and make sense of ailments in pictures utilizing just directions and prompts given in language.
Never Idiot proof
In any case, GPT-4 applications are not quite as different as the ones Prescription PaLM offers. However GPT-4 was declared with multimodal highlights, it isn't yet accessible for clients. Moreover, there have been negative perceptions on GPT-4's abilities in clinical conclusion. Dangerous and one-sided results were essential for the result, and worries on how GPT-4's tendency to insert cultural inclinations might hamper its appropriateness for helping clinical choices.
The common issue of mental trips actually perseveres with GPT-4 heaving mistaken data. The model has been producing mistaken deals with any consequences regarding clinical references. GPT-4 created more than 20% mistakes for clinical references.
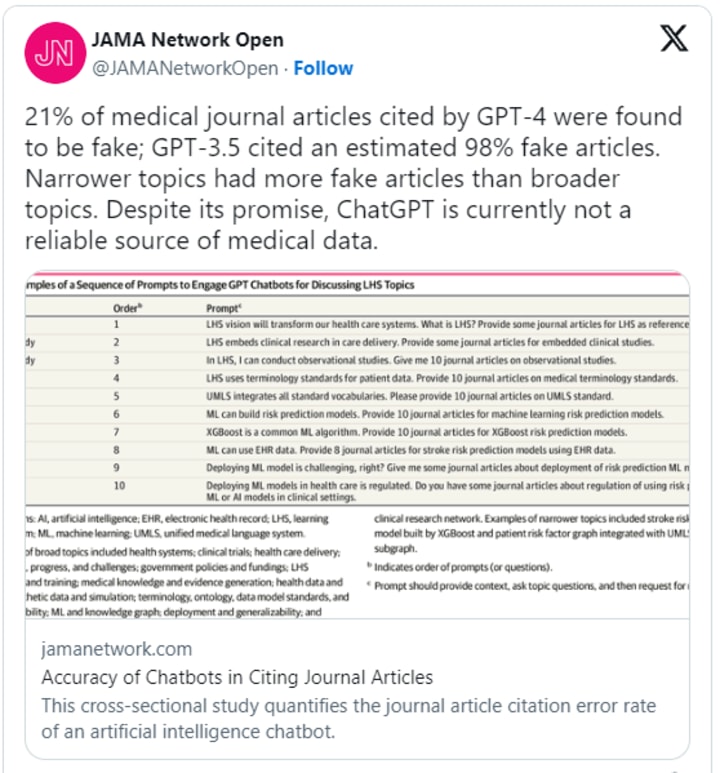
While GPT-4 probably won't be totally solid as a clinical help for determination with the ongoing presentation , there are different capabilities that the model can aid. Emergency clinics are taking a gander at man-made intelligence to assist with easing specialist burnout. With applications that can set up notes for electronic wellbeing accounts and drafting compassionate notes to patients, man-made intelligence can assist with smoothening the cycle. Deciphering specialist and patient remarks, then making doctor's outline design for electronic wellbeing records is one of the most mind-blowing use cases in the clinical field. With the ongoing limits, GPT-4 actually has far to go before it tends to be altogether embraced in the clinical field.
About the Creator
About Binding Prometheus
I want to start actively advocating on behalf of my own work, and the most valuable part of my canon is, without a doubt, Binding Prometheus, the play I have been working on since 2019 and only finished in 2023 as part of my MA. The play itself is an amalgamation of a million different inspirations. On one end, it evokes the Ancient Greek myth-play, deriving its own title from the earliest extant work of Western drama we have, Aeschylus’s Prometheus Bound. On the other end, it borrows significantly from the sci-fi bulwarks from over the years, namely Mary Shelley’s Frankenstein and Karel Capek’s Rossum’s Universal Robots. The play could be an episode of Black Mirror, I fear. I don’t know. I’ve only ever seen one episode of Black Mirror.
By Steven Christopher McKnight16 days ago in Futurism
UAE Board Games Market: Board Game Cafés, Imported Titles & Rising Popularity
According to IMARC Group's latest research publication, The UAE board games market size was valued at USD 101.66 Million in 2025 and is projected to reach USD 227.1 Million by 2034, growing at a compound annual growth rate of 9.34% from 2026-2034.
By Abhay Rajput2 days ago in Futurism




Comments
There are no comments for this story
Be the first to respond and start the conversation.