
Most Frequently Asked Artificial Intelligence Interview Questions In 2023
Artificial Intelligence Interview Questions


1. What Are the Different Types of Machine Learning?
There are three types of machine learning:
Supervised Learning
In supervised machine learning, a model makes predictions or decisions based on past or labeled data. Labeled data refers to sets of data that are given tags or labels, and thus made more meaningful.

Unsupervised Learning
In unsupervised learning, we don’t have labeled data. A model can identify patterns, anomalies, and relationships in the input data.
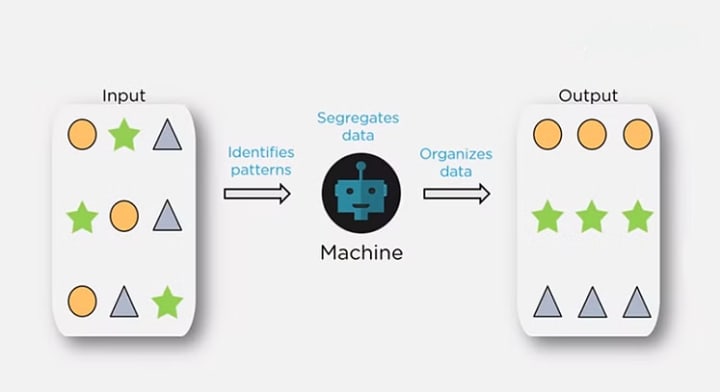
Reinforcement Learning
Using reinforcement learning, the model can learn based on the rewards it received for its previous action.
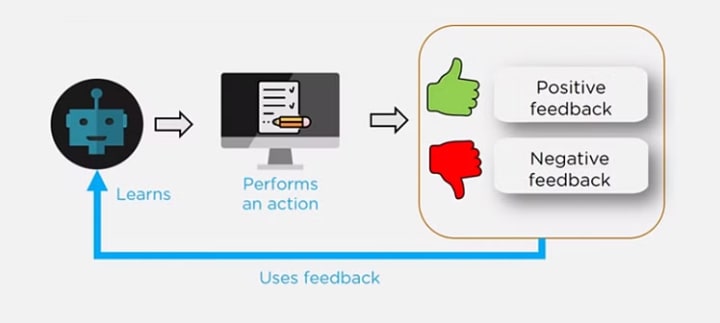
Consider an environment where an agent is working. The agent is given a target to achieve. Every time the agent takes some action toward the target, it is given positive feedback. And, if the action taken is going away from the goal, the agent is given negative feedback.
2. What is Overfitting, and How Can You Avoid It?
The Overfitting is a situation that occurs when a model learns the training set too well, taking up random fluctuations in the training data as concepts. These impact the model’s ability to generalize and don’t apply to new data.
When a model is given the training data, it shows 100 percent accuracy—technically a slight loss. But, when we use the test data, there may be an error and low efficiency. This condition is known as overfitting.
There are multiple ways of avoiding overfitting, such as:
Regularization. It involves a cost term for the features involved with the objective function
Making a simple model. With lesser variables and parameters, the variance can be reduced
Cross-validation methods like k-folds can also be used
If some model parameters are likely to cause overfitting, techniques for regularization like LASSO can be used that penalize these parameters
3. What is ‘training Set’ and ‘test Set’ in a Machine Learning Model? How Much Data Will You Allocate for Your Training, Validation, and Test Sets?
There is a three-step process followed to create a model:
Train the model
Test the model
Deploy the model
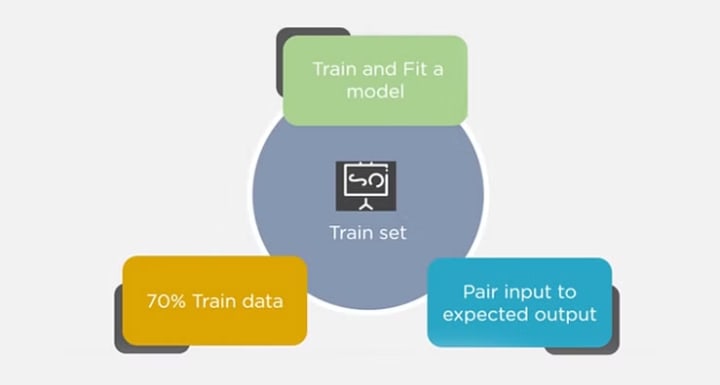
Training Set Test Set
The training set is examples given to the model to analyze and learn70% of the total data is typically taken as the training dataset. This is labeled data used to train the model The test set is used to test the accuracy of the hypothesis generated by the model. Remaining 30% is taken as testing dataset. We test without labeled data and then verify results with labels
Consider a case where you have labeled data for 1,000 records. One way to train the model is to expose all 1,000 records during the training process. Then you take a small set of the same data to test the model, which would give good results in this case.
But, this is not an accurate way of testing. So, we set aside a portion of that data called the ‘test set’ before starting the training process. The remaining data is called the ‘training set’ that we use for training the model. The training set passes through the model multiple times until the accuracy is high, and errors are minimized.
Now, we pass the test data to check if the model can accurately predict the values and determine if training is effective. If you get errors, you either need to change your model or retrain it with more data.
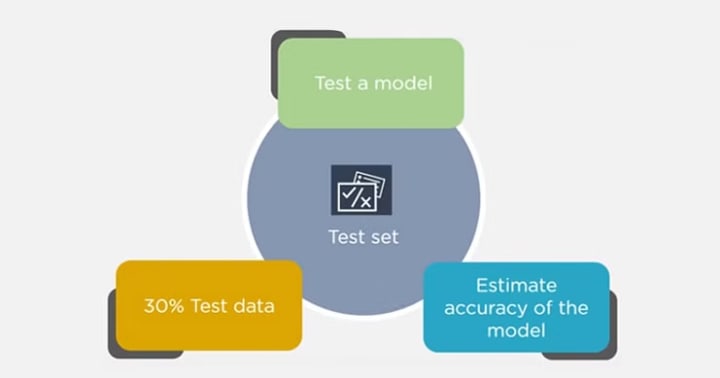
Regarding the question of how to split the data into a training set and test set, there is no fixed rule, and the ratio can vary based on individual preferences.
For More Information: https://www.datacademy.ai/artificial-intelligence-interview-questions/
About the Creator
datacademy ai
Datacademy.ai is an e-learning platform that aims to make education accessible to everyone, no matter where they are located. We believe that education is the key to unlocking one's potential and we are dedicated... see more
Keep reading
More stories from datacademy ai and writers in Education and other communities.
Top AWS Certified DevOps Engineer Interview questions answers on Deployment, Provisioning & Automation
1. Can you explain the deployment process in AWS? The deployment process in AWS involves creating and uploading the application code, setting up necessary infrastructure, and configuring the environment. The steps include creating an AWS Elastic Beanstalk environment, uploading the application code, configuring the environment and deploying the application.
By datacademy ai3 years ago in Education
AI in eLearning Market to Reach USD 12.2 Billion by 2033: Driving Personalized Learning
Market Overview Artificial Intelligence in eLearning represents the integration of machine learning, natural language processing, and advanced analytics into digital learning systems. These technologies allow educational platforms to analyze learner behavior, automate assessments, and provide adaptive learning experiences. AI driven tools can identify learning gaps, recommend personalized study paths, and improve student engagement through interactive digital environments. As education increasingly shifts toward digital platforms, the role of AI technologies in improving learning efficiency continues to expand.
By Roberto Crum3 days ago in Education
Where Energy, Finance, and Technology Converge: Shaping the Future of Modern Infrastructure
In today’s global economy, the boundaries between industries are becoming less distinct. Energy, finance, and technology are no longer separate sectors operating independently. Instead, they are increasingly connected, forming a dynamic ecosystem that supports modern infrastructure and economic development. Navigating the intersection of these three fields requires a deep understanding of how innovation, capital, and energy systems interact.
By Matthew J Smithabout 21 hours ago in Education
Two Grumpy Old Men Solve the Problem
Marty and Steve were two grumpy old men who lived together. They had known each other for years. Marty had been a bachelor all his life. Steve said it was because no one could stand to ever live with. Marty’s standard reply was “Well, you are, so what sort of a moron does that make you!”
By Calvin London3 days ago in Humor




Comments
There are no comments for this story
Be the first to respond and start the conversation.