
How to Optimize RAG Pipelines for Efficient Semantic Search
RAG pipelines have revolutionized semantic search by combining the strengths of retrieval and generation models.
RAG pipelines have revolutionized semantic search by combining the strengths of retrieval and generation models. However, their computational complexity and slow inference speed hinder their adoption in real-world applications.
In this blog, we'll explore practical techniques to optimize RAG pipelines, enabling efficient and accurate semantic search at scale.
Understanding RAG Pipelines
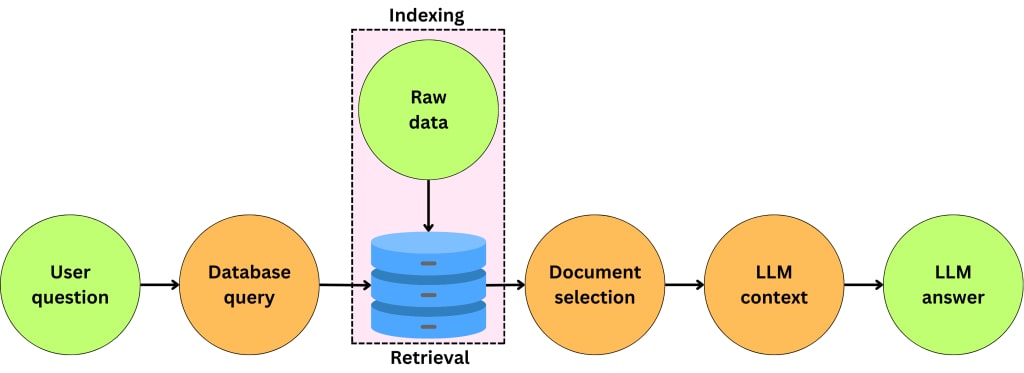
RAG pipelines are a type of artificial intelligence architecture that combines the strengths of retrieval and generation models to enable accurate and efficient semantic search. RAG pipelines consist of two primary components: a retriever model that searches a database to retrieve relevant documents or passages, and a generator model that uses the retrieved information to generate a response or answer.
By leveraging the complementary strengths of these two models, RAG pipelines can provide more accurate and informative results than traditional search methods, making them ideal for applications such as question answering and text summarization.
Optimizing Techniques
Model Pruning
Model pruning is a technique used to optimize RAG pipelines by reducing the size and complexity of the Large Language Model (LLM). By removing redundant or unnecessary weights and connections, model pruning can significantly reduce the computational requirements of the LLM, making it faster and more efficient. This technique is particularly useful for deploying RAG pipelines on resource-constrained devices or in real-time applications where speed is critical. Additionally, model pruning can also improve the accuracy of the LLM by removing noisy or irrelevant weights that can negatively impact performance. By pruning the model, you can optimize the RAG pipeline to provide fast and accurate search results while reducing computational overhead.
Knowledge Distillation
Knowledge distillation is a technique used to optimize RAG pipelines by transferring knowledge from a large, pre-trained LLM to a smaller, more efficient model. By training the smaller model to mimic the behavior of the larger model, knowledge distillation can significantly reduce the computational requirements of the RAG pipeline while maintaining accuracy.
This technique is particularly useful for deploying RAG pipelines on resource-constrained devices or in real-time applications where speed is critical. Additionally, knowledge distillation can also improve the interpretability of the LLM by providing a more transparent and understandable model. By distilling knowledge from the larger model, you can optimize the RAG pipeline to provide fast and accurate search results while reducing computational overhead.
Efficient Indexing and Removal
Efficient indexing and retrieval is a technique used to optimize RAG pipelines by improving the speed and efficiency of the retrieval component. By using efficient indexing algorithms and data structures, such as FAISS or HNSW, you can significantly reduce the time it takes to retrieve relevant documents or passages from the database.
This technique is particularly useful for large-scale RAG pipelines where the retrieval component can become a bottleneck. Additionally, efficient indexing and retrieval can also improve the accuracy of the RAG pipeline by allowing the model to retrieve more relevant documents or passages. By optimizing the indexing and retrieval component, you can optimize the RAG pipeline to provide fast and accurate search results while reducing computational overhead.
Conclusion
To create an optimized RAG pipeline, it's essential to combine the techniques discussed earlier. By applying model pruning, knowledge distillation, and efficient indexing and retrieval, you can significantly reduce the computational requirements and improve the accuracy of your RAG pipeline. Start by pruning the Large Language Model (LLM) to reduce its size and complexity, followed by knowledge distillation to transfer knowledge to a smaller model. Next, implement efficient indexing and retrieval algorithms to speed up the retrieval component. By combining these techniques, you can create a highly optimized RAG pipeline that provides fast and accurate search results.
To take your RAG pipeline to the next level, consider using Vectorize.io, a platform that provides a scalable and efficient way to build, deploy, and manage embedding models, including RAG pipelines.
By leveraging Vectorize.io, you can focus on developing your RAG pipeline while leaving the heavy lifting to the platform, resulting in faster development, deployment, and iteration cycles.
About the Creator
Keep reading
More stories from Vectorize io and writers in Education and other communities.
How are Pinecone and Chroma different
In today's data-driven world, the need for efficient and scalable ways to manage and query large datasets is more critical than ever. Vector databases have become quite significant in artificial intelligence, serving as the backbone for efficient data storage and management in neural network applications.
By Vectorize io2 years ago in Education
How Spending Time Together Strengthens Family Relationships Long Term
Spending meaningful time together is one of the most powerful ways families can build stronger, healthier relationships that last for years. Even though busy schedules and constant distractions often pull people in different directions, intentional togetherness helps families stay emotionally connected.
By Joe Sottolano6 days ago in Education
The Growing Importance of Technical Skills in Financial Analysis
The financial sector is undergoing a significant transformation, driven by the growing availability of data and rapid technological advancements. In this new landscape, financial analysts are expected to go beyond traditional tools and embrace a broader set of technical skills. These skills not only improve the speed and accuracy of analysis but also enable more profound insights, better forecasting, and stronger collaboration across departments. As businesses face more complex challenges, technical fluency has become an essential asset for modern financial professionals.
By Anthony Qi5 days ago in Education




Comments (1)
I want to give a clap.